
搶先一步
VMware 提供培訓和認證,以加速您的進程。
了解更多#簡介#
在開發串流應用程式時,一個常見的問題是:「每秒可以處理多少個事件?」。本部落格文章的主要目的是回答這個問題,而不會陷入經典的效能評測 難題,也就是效能評測與「效能行銷」之間的差異。訊息中間件供應商提供的「原生」效能評測應用程式的常見方法是專注於原始資料傳輸速度,而不進行訊息資料的序列化或反序列化,也不進行任何資料處理。在本系列文章的第 1 部分中,我們將採用這種方法。
我們的測試在 Spring XD 中使用了直接綁定(記憶體內)和 Apache KafkaⓇ 傳輸,其中生產者和消費者同時運行。此測試情境模擬了即時串流處理,而不是僅有生產者或僅有消費者的測試套件。測試情境使用單個容器進行直接綁定,並在使用 Kafka 傳輸時使用多個容器。每個測試都改變了事件(訊息)的大小,結果顯示為每秒消耗的總訊息數和 MB 數。在 Kafka 傳輸測試的情況下,我們使用 Kafka 提供的效能工具為我們提供已配置基礎架構的基準效能評測。##什麼是 Spring XD?## Spring XD 是一個統一的、分散式的、可擴展的系統,用於資料擷取、即時分析、批次處理和資料匯出。該專案的目標是簡化大數據或企業串流/批次應用程式的開發。有關 XD 的更多資訊,請參閱 此處。##架構## 所有測試都使用 RackSpace OnMetal 伺服器運行,以確保所有服務的網路速度,並為我們的 Kafka 測試提供適當的磁碟寫入速度。有關此選擇的更多詳細資訊,請參閱下文。使用的伺服器規格如下:###伺服器實例類型###
###網路:### 所有測試都在 10 Gigabit 網路上運行 Spring XD,平均速度為 1117 MB/s 或 8.936 Gbps。我們使用 iperf 來確定網路效能,客戶端使用以下命令 iperf -c <iperf 伺服器的 ip> -f Mbytes,伺服器使用 iperf -s。 ###磁碟:### 所有需要高效能磁碟寫入的測試都在 OnMetal IO 資料磁碟上實現。這些裝置的平均磁碟寫入速度約為 ~934 MB/s。用於驗證磁碟寫入速度的命令是 dd if=/dev/zero of=/data1/largefile bs=1M count=10000 conv=fdatasync。dd 命令上的 fdatasync 需要在退出前完成「同步」,從而驗證資料是否完全寫入磁碟而不是快取。##工具## 用於測試傳輸的兩個主要工具是 load-generator 來源和 throughput 接收器模組,可以在 github 的 spring-xd-modules 專案中找到。load-generator 來源模組在記憶體中產生資料,並且可以配置為發送特定數量的特定大小的訊息。throughput 模組是一個接收器,用於計算收到的訊息並定期將觀察到的吞吐量報告給日誌。
#傳輸測試# ##直接綁定傳輸## 為了消除網路延遲,有時希望允許位於同一位置的連續模組直接通訊,而不是使用配置的遠端傳輸。僅當每個生產者和消費者(管道任一側綁定的模組)「對」都保證位於同一個 JVM 中時,Spring XD 才會預設建立直接綁定。此效能評測的目的是顯示使用直接綁定的單個 XD 容器的訊息吞吐量。在此情境中,我們在單個容器中發送和消耗了 5 億條訊息。以下串流定義用於捕獲 1000 位元組訊息測試的結果:stream create directBindingTest --definition "load-generator --messageCount=500000000 --messageSize=1000 | throughput" stream deploy directBindingTest --properties module.*.count=0 下圖顯示了訊息大小為 100、1000、10000 和 100000 位元組時的每秒訊息/MB:###每秒訊息數### 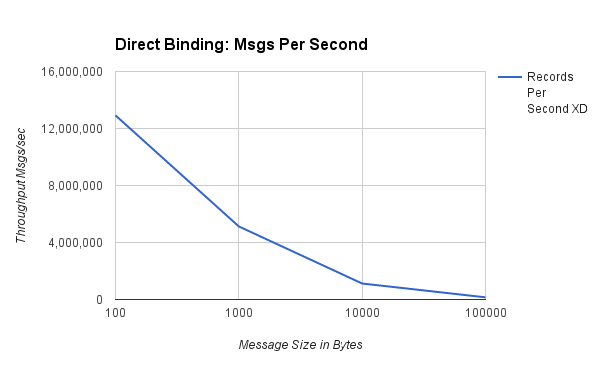 ###每秒 MB 數###
###每秒 MB 數### 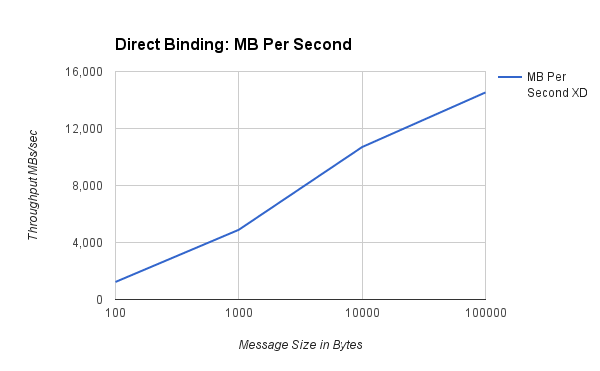
| 訊息大小 | 每秒訊息數 XD | 每秒 MB 數 XD |
|---|---|---|
| 100 | 12,919,560 | 1,232 |
| 1,000 | 5,126,920 | 4,893 |
| 10,000 | 1,121,921 | 10,699 |
| 100,000 | 152,364 | 14,530 |
圖表顯示,隨著訊息大小的增加,速率會降低,但整體資料吞吐量會增加。對於 100 到 1,000 位元組範圍內的典型大小的有效負載,我們能夠使用單個線程每秒推送 5-12 百萬個事件。以這種規模執行小型操作的成本(例如訪問雜湊表中的資料)意味著任何資料處理都會顯著降低速率。
##Kafka 傳輸## ###測試拓撲###
對於 Kafka 的測試,我們創建了以下拓撲
在三個 OnMetal I/O 實例上設置了一個三個 Broker 的 Kafka 叢集。每個 Kafka 實例都有兩個沒有 RAID 的 SSD。Kafka Broker 和 XD 之間共享一個 Zookeeper 實例,並將其部署在一個 Compute v1 Rackspace 實例上。XD 叢集部署在 2 個 OnMetal Compute 實例上。RS(RackSpace) 實例一託管一個 XD-Admin、一個 HSQLDB 和一個 xd-container。RS(RackSpace) 實例二託管一個 xd-container。
####實例類型選擇#### 實例類型的選擇基於處理器速度、磁碟寫入速度和可以處理資料量的網路。最初,這些測試計劃用於 EC2,但我們發現臨時磁碟寫入速度太慢(約 ~75 MB/s),Kafka 無法以其峰值效能運行。我們計劃在新發布的 D2 實例類型上重新運行測試。我們決定使用 Rackspace OnMetal I/O 來利用高效能 SSD(約 ~934 MB/s)。 ####測試#### 此效能評測的目的是顯示在不同機器上的兩個不同 XD 容器上運行,並使用 Kafka 作為傳輸的來源(發布者)和接收器(消費者)的訊息吞吐量。此效能評測的目標是從 Kafka 自己的測試工具中捕獲原生統計資訊,並將其與 Spring XD 針對同一組測試的結果進行比較。這種比較很重要,因為 XD 不使用標準的 Kafka Consumer API,而是使用 Spring Integration Kafka Adapter,它增加了額外的功能,例如控制從哪個偏移量消費以及從主題消費哪個分割區。在每種情況下,都會創建一個具有六個分割區且複製因子為三的主題。生產者將放置在 RS 實例一上,消費者將放置在 RS 實例二上。這些測試的所有有效負載僅使用位元組陣列資料進行操作。因此,對於這些測試,Spring XD 的 Kafka 傳輸模式設置為 raw。Raw 模式表示 Spring XD 不會嵌入標頭,並將序列化的處理留給使用者。
使用 Kafka 的效能工具,以與 Benchmarking Apache Kafka: 2 Million Writes Per Second 中演示的相同方式,我們希望確定 Kafka 叢集的基準速度。在下面的範例中,以下生產者/消費者命令用於 1000 位元組訊息測試的這些結果
生產者: ./bin/kafka-topics.sh --zookeeper <ip>:2181 --create --topic $1 --partitions 6 --replication-factor 3 ./bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformance $1 300000000 1000 -1 acks=1 bootstrap.servers=<ip>:9092,<ip>:9092,<ip>1:9092 batch.size=128000 消費者: ./bin/kafka-run-class.sh ./bin/kafka-consumer-perf-test.sh --zookeeper <ip>:2181 --messages 300000000 --topic $1 --threads 1
Spring XD 1.2 使用新的 Spring Integration Kafka adapter,它提供了比標準 Kafka 客戶端庫更豐富的功能集。XD 的配置是開箱即用的,除了我們在 servers.yml 中設置了以下配置以匹配原生測試中使用的配置
要閱讀有關這些配置的更多資訊,請查看我們位於 此處 的文檔。
以下串流用於 1000 位元組訊息測試的這些結果: stream create myTest --definition "load-generator --messageCount=300000000 --messageSize=1000 | throughput" stream deploy myTest ####吞吐量#### #####每秒訊息數##### 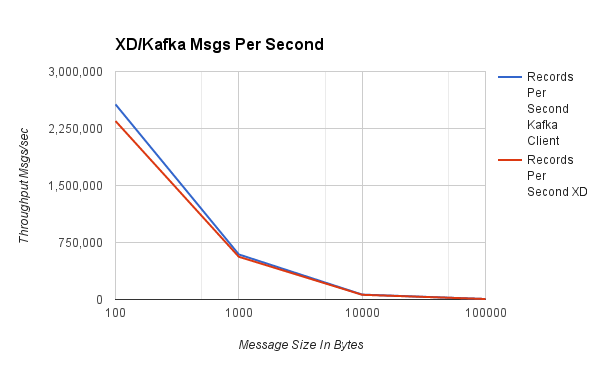
| 訊息大小 | 每秒訊息數 Kafka 客戶端 | 每秒訊息數 XD |
|---|---|---|
| 100 | 2,567,657 | 2,348,289 |
| 1,000 | 592,881 | 562,113 |
| 10,000 | 64,806 | 61,985 |
| 100,000 | 6,505 | 6,341 |
| #####每秒訊息數##### |
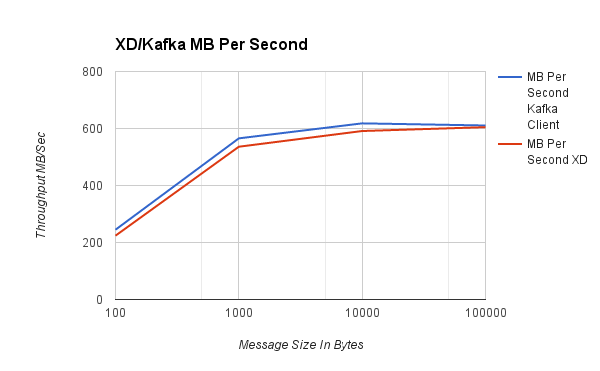
| 訊息大小 | 每秒 Mb 數 Kafka 客戶端 | 每秒 Mb 數 XD |
|---|---|---|
| 100 | 245 | 224 |
| 1,000 | 565 | 536 |
| 10,000 | 618 | 591 |
| 100,000 | 611 | 605 |
與直接綁定效能評測一樣,圖表顯示隨著訊息大小的增加,速率會降低,但整體資料吞吐量會增加。對於 100 到 1,000 位元組範圍內的典型大小的有效負載,我們能夠使用單個線程每秒推送 600K 到 ~2 百萬個事件。重要的是要注意,Spring XD 的效能評測 - 基於更豐富功能的消費者庫 - 在 Kafka 原生客戶端 API 的效能評測的 8% 範圍內。另請注意,在 1000 到 10,000 位元組訊息大小之間,單個生產者可以達到約一半的 10Gb 網路容量。在未來的測試中,我們將展示多個生產者和消費者的效能評測,以顯示 XD 如何擴展以及其他調整參數(例如批次大小)如何影響效能。
#結論# 上述基準測試顯示 Spring XD 可以滿足高效能串流使用案例的需求。它們也顯示,相較於原生 Kafka 高階消費者函式庫,Spring XD 使用的 Spring Integration Kafka (SIK) 客戶端函式庫所引入的額外負擔非常小,同時還提供了額外的功能,例如對偏移量和分割區的控制。因此,您可以利用 Spring XD 程式設計模型以及 SIK 消費者 API 的功能,對效能的影響極小。
#後續步驟# 雖然有些使用案例主要集中在資料直通傳輸,但大多數使用案例都會涉及對 Payload 的一些處理。此外,我們只使用了一個處理執行緒。在未來的部落格文章中,我們將展示 XD 如何隨著更多容器實例擴展、使用流行的函式庫反序列化/序列化物件時,訊息速率如何受到影響,以及多個執行緒和反應式程式設計如何也有助於提高每個 JVM 進程的速率。敬請關注!
編者註:©2015 Pivotal Software, Inc. 保留所有權利。 Apache 和 Apache Kafka 是 Apache Software Foundation 在美國和/或其他國家的註冊商標或商標。