
領先一步
VMware 提供訓練和認證,以加速您的進度。
了解更多JVM 可能是一個複雜的巨獸。 幸運的是,大部分的複雜性都在幕後,我們作為應用程式開發人員和部署人員通常不必太擔心。 隨著基於容器的部署策略的興起,一個需要關注的複雜領域是 JVM 的記憶體佔用量。
JVM 將其記憶體分為兩個主要類別:堆積記憶體和非堆積記憶體。 堆積記憶體是人們通常最熟悉的部分。 它是儲存應用程式建立的物件的地方。 它們會一直存在,直到不再被引用並被垃圾收集為止。 通常,應用程式使用的堆積量會隨著目前負載而波動。
JVM 的非堆積記憶體分為幾個不同的區域。 我們可以使用 HotSpot VM 的 原生記憶體追蹤 (NMT) 來檢查其在這些區域的記憶體使用情況。 請注意,雖然 NMT 不會追蹤所有原生記憶體使用情況(例如,它不會追蹤第三方原生程式碼記憶體配置),但對於一類典型的 Spring 應用程式來說,它就足夠了。 可以透過使用 -XX:NativeMemoryTracking=summary 啟動應用程式,然後使用 jcmd <pid> VM.native_memory summary 來顯示記憶體使用情況摘要來使用 NMT。
讓我們透過查看一個應用程式(在本例中是我們的老朋友 Petclinic)來說明 NMT 的使用。 下面的圓餅圖顯示了使用 48MB 最大堆積 (-Xmx48M) 啟動 Petclinic 時,NMT 報告的 JVM 記憶體使用情況(減去其自身開銷)
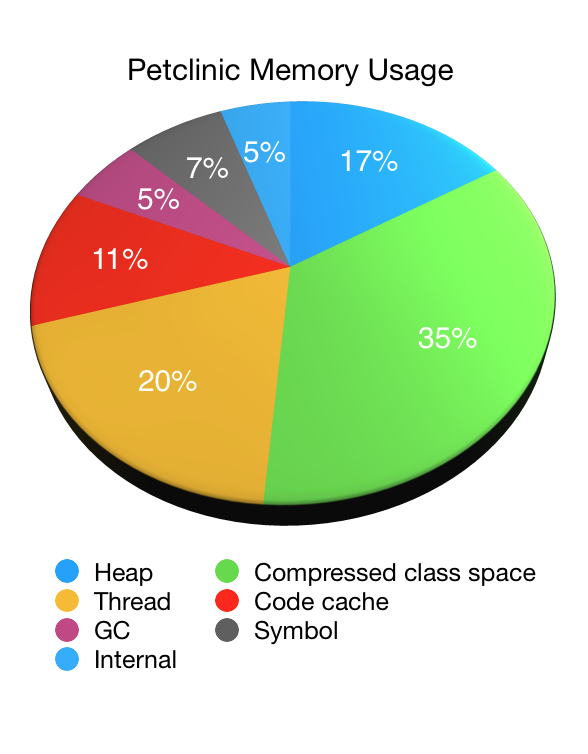
正如您所看到的,非堆積記憶體佔 JVM 記憶體使用量的絕大部分,而堆積記憶體僅佔總記憶體使用量的六分之一。 在這種情況下,大約是 44MB(其中 33MB 在垃圾收集後立即被使用)。 非堆積記憶體使用量總計為 223MB。
MaxMetaspaceSize 限制。 是已載入類別數量的函數。ReservedCodeCacheSize 限制。 可以透過調整 JIT 來減少,例如,停用分層編譯。與堆積記憶體相比,非堆積記憶體在負載下不太可能變化。 一旦應用程式載入了它將使用的所有類別,並且 JIT 完全預熱後,事情就會進入穩定狀態。 要查看壓縮類別空間使用量的減少,需要對載入類別的類別載入器進行垃圾收集。 這在過去更為常見,當時應用程式部署到 servlet 容器或應用程式伺服器 – 當應用程式解除部署時,應用程式的類別載入器會被垃圾收集 – 但在現代應用程式部署方法中很少發生。
配置 JVM 以有效利用給定的可用 RAM 量並不容易。 如果您使用 -Xmx16M 啟動 JVM 並期望它最多使用 16MB 的 RAM,您將會遇到一個糟糕的驚喜。
調整 JVM 大小時的一個有趣領域是 JIT 的程式碼快取。 預設情況下,HotSpot JVM 將使用高達 240MB。 如果程式碼快取太小,JIT 將耗盡空間來儲存其輸出,並且效能將因此受到影響。 如果快取太大,可能會浪費記憶體。 在調整程式碼快取的大小時,重要的是要查看對應用程式記憶體使用量及其效能的影響。
在 Docker 容器中運行時,最新版本的 Java 現在知道容器的記憶體限制,並嘗試相應地調整 JVM 的大小。 遺憾的是,這種大小調整通常會過度分配非堆積記憶體並低估堆積記憶體。 假設您有一個應用程式在具有 2 個 CPU 和 512MB 可用記憶體的容器中運行。 您希望它能夠處理更多的負載,因此您將 CPU 加倍到 4 個,並將記憶體增加到 1GB。 如上所述,堆積使用量通常會根據負載而變化,而非堆積使用量則要少得多。 因此,我們希望將額外的 512MB 記憶體的大部分分配給堆積,以應對增加的負載。 遺憾的是,JVM 預設情況下不會這樣做,而是會更平均地在其堆積和非堆積區域之間分配額外的記憶體。
值得慶幸的是,CloudFoundry 團隊對 JVM 的記憶體佔用量有大量的知識。 如果您將應用程式推送到 CloudFoundry,則建置套件會自動為您應用此知識。 如果您未使用 CloudFoudry,或者您想更深入地了解如何調整 JVM 的大小,則 設計文件適用於第三版 Java 建置套件記憶體計算器提供了一些強烈建議的進一步閱讀材料。
我們花費大量時間在 Spring 團隊中思考效能和記憶體利用率,同時考慮堆積和非堆積記憶體使用量。 限制非堆積記憶體使用量的一種方法是使 Framework 的部分盡可能通用。 這方面的一個例子是使用反射來建立依賴關係並將其注入到應用程式的 bean 中。 由於使用了反射,因此使用的 Framework 程式碼量保持不變,無論應用程式包含多少個 bean。 我們使用基於堆積的快取來最佳化啟動時間,並在啟動完成後清除此快取。 然後,垃圾收集器可以輕鬆地回收堆積記憶體,從而使盡可能多的記憶體可用於應用程式來處理其工作負載。