
取得領先
VMware 提供訓練和認證,助您加速進展。
了解更多我很高興代表 Spring Batch 團隊宣布 Spring Batch 4.2.0.RC1 的發佈。 我們一直在核心框架中進行一些效能改進,這篇文章重點介紹了主要的變更。
我們進行了一些效能改進,包括:
啟動分區化的步驟是框架未經良好優化的區域。 在這個版本中,我們深入研究了分區過程,以找出這個效能問題的根本原因。 分區過程的主要步驟之一是找到最後的步驟執行(以查看目前的執行是否為重新啟動)。 我們發現查詢最後的步驟執行涉及從給定 Job 實例的所有 Job 執行中,在記憶體中載入所有步驟執行,這顯然效率低下!
我們用一個 SQL 查詢替換了這段程式碼,該查詢在資料庫層級執行查找,只傳回最後的步驟執行。 結果非常出色:根據我們的基準測試 partitioned-step-benchmark,使用這種方法將步驟執行分區成 5000 個分區的速度幾乎快了 10 倍
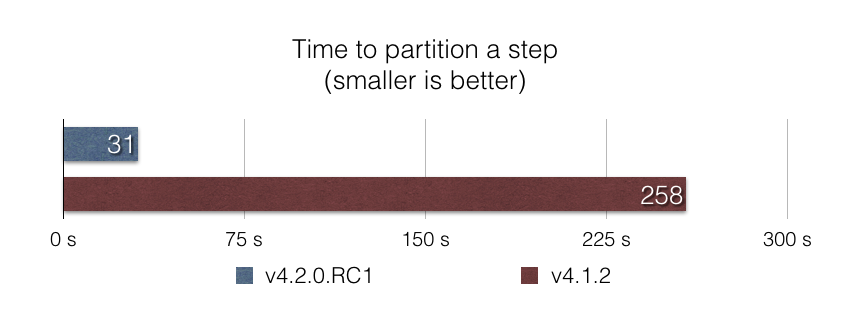
執行 Job 時可能會出錯,為了避免資料損壞,優雅地停止破壞性的 Job 應該快速而有效率。 在 v4.1 之前,使用 CommandLineJobRunner 停止 Job 的效能很差,因為要將所有 Job 執行載入記憶體中,才能找出 Job 執行是否正在執行。 使用這種方法,在具有數千個 Job 執行的生產資料庫中,停止 Job 可能需要數分鐘!
在這個版本中,我們透過使用在資料庫層級進行篩選的 SQL 查詢來優化停止過程。 再次,結果令人印象深刻:根據我們的基準測試 stop-benchmark,在資料庫中具有給定 Job 的 100,000 個 Job 執行時,使用這種方法停止 Job 的速度幾乎快了 40 倍
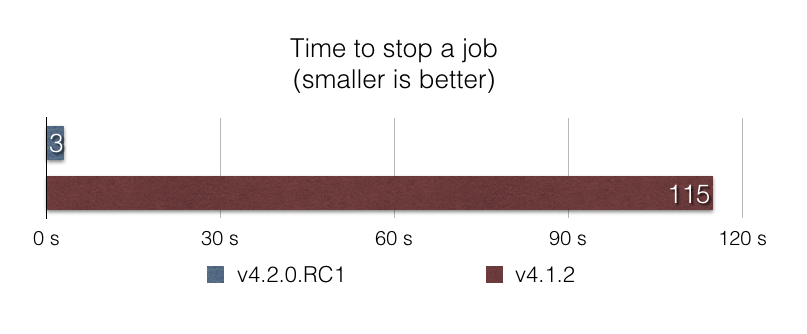
JpaItemWriter 更快的寫入JpaItemWriter 使用 javax.persistence.EntityManager#merge 函數在 JPA 持續性內容中寫入項目。 當項目的持續性狀態未知或已知為更新時,這是合理的。 然而,在許多已知資料為新且應被視為插入的檔案擷取 Job 中,使用 javax.persistence.EntityManager#merge 的效率不高。
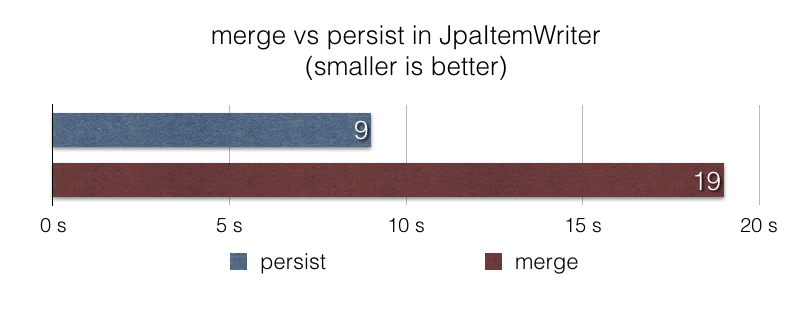
在這個版本中,我們在 JpaItemWriter 中引入了一個新選項,在這種情況下使用 persist 而不是 merge。 根據我們的基準測試 jpa-writer-benchmark,使用這個新選項,使用 JpaItemWriter 將 100 萬個項目插入資料庫的檔案擷取 Job 的速度快了 2 倍
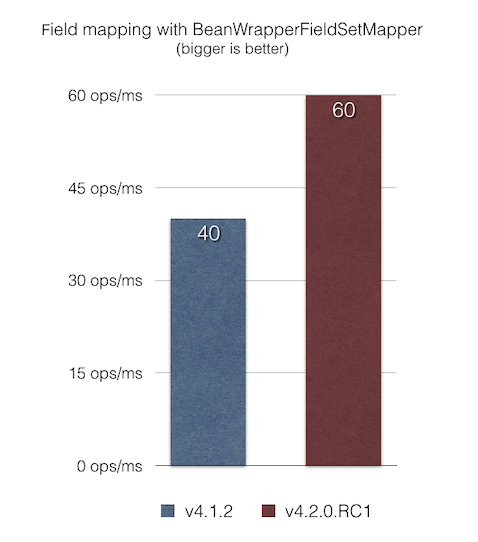
BeanWrapperFieldSetMapper 優化的 Bean 映射BeanWrapperFieldSetMapper 提供了一個不錯的功能,讓我們可以使用給定 JavaBean 的欄位名稱的模糊比對(駝峰式大小寫、巢狀屬性等等)。 然而,當欄位名稱與欄位名稱比對時,可以透過將 distanceLimit 參數設定為 0 來啟用精確比對。
在這個版本中,我們修復了 BeanWrapperFieldSetMapper 中的效能問題,即使要求精確比對(透過設定 distanceLimit=0),它也會在每次迭代中使用反射來內省欄位名稱。 根據我們的 JMH 基準測試 bean-mapping-benchmark,結果是項目映射現在比以前的版本快了 1.5 倍
請注意,這些數字可能因您的情況而異。 我們鼓勵您嘗試 Spring Batch 4.2.0.RC1(可以使用 Spring Boot 2.2.0.M6 使用)並分享您的意見反應。 請參閱 4.2.0.RC1 和 4.2.0.M3 版本的變更日誌,以取得完整的變更清單。
隨時在 Twitter 上 ping @michaelminella 或 @b_e_n_a_s,或在 StackOverflow 或 Gitter 上提出您的問題。 如果您發現任何問題,請在 Jira 上開啟一個工單。
我們計劃穩定這個新的候選版本,以便於 2019 年 9 月 30 日發佈即將推出的 Spring Batch 4.2.0.RELEASE。 敬請期待!
所有基準測試均在 Macbook Pro 16Go RAM、2.9 GHz Intel Core i7 CPU、MacOS Mojave 10.14.5、Oracle JDK 1.8.0_201 上執行。 您可以在以下連結中找到所有基準測試的原始程式碼