
搶先一步
VMware 提供訓練和認證,以加速您的進展。
深入瞭解本文是部落格系列文章的一部分,探討基於 Java Function 重新設計的 Spring Cloud Stream 應用程式。在本集中,我們將深入研究檔案供應器及其 Spring Cloud Stream 檔案來源對應項。我們也將看到 MongoDB 消費者及其對應的 Spring Cloud Stream 接收器。最後,我們將示範如何在 Spring Cloud Data Flow 上將檔案來源和 MongoDB 接收器協調為一個管線。
以下是本部落格系列的所有先前部分。
檔案擷取和從這些檔案讀取資料是典型的企業用例。許多企業數十年來一直依賴不同層級的檔案設施來執行關鍵任務系統。數兆位元組的資料以檔案形式在網際網路和企業內部網路中傳輸。例如,想像一個銀行資料中心,它每秒都從其所有分行、ATM 和 POS 交易中接收檔案形式的資料,然後需要對其進行處理並放入其他系統中。這只是一個領域,但在數十萬個範例中,檔案處理處於許多企業的關鍵路徑上。在許多舊版系統中,編寫了許多自訂應用程式,每個應用程式都採用自己的方式來處理這些用例。多年來,Spring Integration 一直提供 檔案支援 作為通道配接器。這些組件可以實現為 function,並且在從檔案讀取的情況下,我們可以提供一個通用的 Supplier function,該 function 可重複使用並注入到終端使用者應用程式中。在以下章節中,我們將更詳細地了解此 function 抽象及其各種使用情境。
檔案供應器 是一個組件,它實作為 java.util.function.Supplier bean,當被調用時,它將傳遞給定目錄中檔案的內容。檔案供應器具有以下簽章。
Supplier<Flux<Message<?>>>
供應器的使用者可以訂閱傳回的 Flux<Message<?>,它是目錄中訊息或檔案物件本身的串流。
為了調用檔案供應器,我們需要指定一個目錄來輪詢檔案。目錄資訊是必要的,並且必須通過組態屬性 file.supplier.directory 提供。預設情況下,供應器將產生 byte[] 格式的資料,但它也通過組態屬性 file.consumer.mode 支援兩種額外的檔案消費模式。支援的其他值為 lines 和 ref。檔案消費模式 lines 將一次消費檔案內容一行。這對於讀取文字檔案(例如 CSV 檔案和其他結構化文字資料)非常有用。ref 模式將提供實際的 File 物件。預設情況下,檔案供應器還會阻止讀取它之前已讀取的相同檔案。這通過屬性 file.supplier.preventDuplicates 控制。
檔案供應器是一個可重複使用的 Spring bean,我們可以將其注入到終端使用者自訂應用程式中。一旦注入,就可以直接調用它,並與資料的自訂處理相結合。以下是一個範例。
@Autowired
Supplier<Flux<Message<?>>> fileSupplier;
public void consumeDataAndSendEmail() {
Flux<Message<?> data = fileSupplier.get();
messageFlux.subscribe(t -> {
if (t == something)
//send the email here.
}
}
}
在上面的虛擬程式碼中,我們注入了檔案供應器 bean,然後使用它來調用其 get 方法以取得 Flux。然後我們訂閱該 Flux,並且每次通過 Flux 接收到任何資料時,都會套用一些篩選,並根據該資料採取動作。這只是一個簡單的說明,展示了我們如何重複使用檔案供應器。當您在實際應用程式中嘗試此操作時,您可能需要在實作中進行更多調整,例如將接收到的資料的預設資料類型從 byte[] 轉換為其他類型,然後再執行條件檢查,或將預設檔案讀取模式從 content 變更為 lines 等。
當檔案供應器與 Spring Cloud Stream 結合以使其成為 檔案來源 時,它會變得更加強大。正如我們在先前的部落格中看到的那樣,此供應器已預先封裝了 Kafka 和 RabbitMQ binder 在 Spring Cloud Stream 中,以使其成為可作為 Spring Boot 應用程式執行的 uber jar。讓我們看看如何取得此 uber jar 並將其作為獨立程式執行。
第一步,繼續取得此具有 Apache Kafka 變體的檔案來源。
wget https://repo.spring.io/libs-snapshot-local/org/springframework/cloud/stream/app/file-source-kafka/3.0.0-SNAPSHOT/file-source-kafka-3.0.0-SNAPSHOT.jar
確保您的 Kafka 在預設埠上執行。
現在是時候獨立執行檔案來源了。
java -jar file-source-kafka-3.0.0-SNAPSHOT.jar --file.supplier.directory=/tmp/data-files --file.consumer.mode=lines --spring.cloud.stream.bindings.output.destination=file-data
預設情況下,Spring Cloud Stream 預期輸出繫結為 fileSupplier-out-0(因為 fileSupplier 是供應器 bean 名稱)。但是,當產生這些應用程式時,此輸出繫結會被覆寫為 output。這樣做是為了在 Spring Cloud Data Flow 上執行此來源應用程式時滿足某些需求。
我們也要求應用程式讀取落在 /tmp/data-files 目錄中的檔案,並一次消費它們一行(使用模式 lines)。
監看 kafka 主題 file-data。使用 kafkacat 工具,您可以執行此操作
kafkacat -b localhost:9092 -t file-data
現在,將一些檔案放入 /tmp/data-files 目錄中。您將看到資料到達 file-data Kafka 主題中,檔案中的每一行代表一個 Kafka 記錄。
如果您想將檔案限制為某些模式,則可以使用屬性 file.supplier.filenamePattern 使用簡單的命名模式,或使用屬性 file.supplier.filenameRegex 使用更複雜的 regex based 模式。
正如我們在 本部落格系列的第二部分 中看到的那樣,所有現成的 Spring Cloud Stream 來源應用程式都已自動組態了多個現成的通用處理器。您可以啟用這些處理器作為檔案來源的一部分。以下是一個範例,我們在其中執行檔案來源並接收資料,然後在將消費的資料傳送到中介軟體上的目的地之前對其進行轉換。
java -jar file-source-kafka-3.0.0-SNAPSHOT.jar --file.supplier.directory=/tmp/data-files --file.consumer.mode=lines --spring.cloud.stream.bindings.output.destination=file-data --spring.cloud.function.definition=fileSupplier|spelFunction --spel.function.expression=payload.toUpperCase()
通過為 spring.cloud.function.definition 屬性提供值 fileSupplier|spelFunction,我們正在啟用與檔案供應器組成的 spel function。然後,我們提供一個 SpEL 運算式,我們想要使用該運算式來轉換使用 spel.function.expression 的資料。
還有其他幾個 function 可用於以這種方式組合。請查看 此處 以取得更多詳細資訊。
MongoDB 消費者提供了一個 function,允許使用者從外部系統接收資料,然後將該資料寫入 MongoDB。我們可以將消費者 bean 直接用於我們的自訂應用程式中,以將資料插入 MongoDB 集合中。以下是 MongoDB 消費者 bean 的類型簽章。
Consumer<Message<?>> mongodbConsumer
一旦注入到自訂應用程式中,使用者可以直接調用消費者的 accept 方法,並提供一個 Message<?> 物件,以將其酬載傳送到 MongoDB 集合。
使用 MongoDB 消費者時,集合是必要的屬性,並且必須通過 mongodb.consumer.collection 進行組態。
與檔案來源的情況一樣,Spring Cloud Stream 現成的應用程式已經使用 MongoDB 消費者提供了 MongoDB 接收器。接收器適用於 Kafka 和 RabbitMQ binder 變體。當用作 Spring Cloud Stream 接收器時,MongoDB 消費者會自動組態為接受來自各別中介軟體系統的資料,例如,來自 Kafka 主題或 RabbitMQ 交換的資料。
讓我們花幾分鐘時間驗證我們可以獨立執行 MongoDB 接收器。
在終端機視窗上執行以下命令。
docker run -d --name my-mongo \
-e MONGO_INITDB_ROOT_USERNAME=mongoadmin \
-e MONGO_INITDB_ROOT_PASSWORD=secret \
-p 27017:27017 \
mongo
docker exec -it my-mongo /bin/sh
這將使我們進入正在執行的 docker 容器中的 shell 工作階段。在 shell 中調用以下命令。
# mongo
> use admin
> db.auth('mongoadmin','secret')
1
> db.createCollection('test_collection’')
{ "ok" : 1 }>
現在我們已經設定了 MongoDB,讓我們獨立執行接收器。
wget https://repo.spring.io/libs-snapshot-local/org/springframework/cloud/stream/app/mongodb-sink-kafka/3.0.0-SNAPSHOT/mongodb-sink-kafka-3.0.0-SNAPSHOT.jar
java -jar mongodb-sink-kafka-3.0.0-SNAPSHOT.jar --mongodb.consumer.collection=test_collection --spring.data.mongodb.username=mongoadmin --spring.data.mongodb.password=secret --spring.data.mongodb.database=admin --spring.cloud.stream.bindings.input.destination=test-data-mongo
將一些 JSON 資料插入 Kafka 主題 test-data-mongo。例如,您可以使用 Kafka 隨附的 console producer 腳本,如下所示。
/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test-data-mongo
然後產生像這樣的資料
{"hello":"mongo"}
前往我們在上面的 Docker shell 上啟動的終端機上的 MongoDB CLI。
db.test_collection.find()
我們通過 Kafka 主題輸入的資料應顯示為輸出。
獨立執行檔案來源和 MongoDB 很好,但 Spring Cloud Data Flow 使它們可以非常輕鬆地作為管線執行。基本上,我們想要協調一個等效於 File Source | Filter | MongoDB 的流程。
本系列部落格中的一篇 專門介紹了如何執行 Spring Cloud Data Flow 並將應用程式部署為串流的所有詳細資訊。如果您不熟悉執行 Spring Cloud Data Flow,請查看該部落格。下面,我們簡要介紹設定 Spring Cloud Data Flow 所涉及的步驟。
首先,我們需要取得用於執行 Spring Cloud Data Flow 的 docker-compose 檔案。
wget -O docker-compose.yml https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v2.6.0/spring-cloud-dataflow-server/docker-compose.yml
此外,取得此額外的 docker-compose 檔案以執行 MongoDB。
wget -O mongodb.yml https://raw.githubusercontent.com/spring-cloud/stream-applications/gh-pages/files/mongodb.yml
我們需要設定一些環境變數才能正確執行 Spring Cloud Data Flow。
export DATAFLOW_VERSION=2.6.0
export SKIPPER_VERSION=2.5.0
export STREAM_APPS_URI=https://repo.spring.io/libs-snapshot-local/org/springframework/cloud/stream/app/stream-applications-descriptor/2020.0.0-SNAPSHOT/stream-applications-descriptor-2020.0.0-SNAPSHOT.stream-apps-kafka-maven
現在我們已準備就緒,是時候開始執行 Spring Cloud Data Flow 和所有其他輔助組件了。
docker-compose -f docker-compose.yml -f mongo.yml up
一旦 SCDF 啟動並執行,請前往 http://localhost:9393/dashboard。然後前往左側的 Streams 並選擇 Create Stream。從來源應用程式中選擇 File,從處理器中選擇 Filter,然後從接收器應用程式中選擇 MongoDB。按一下選項並選擇以下屬性。以下是選取所有屬性後應顯示的外觀螢幕擷取畫面。
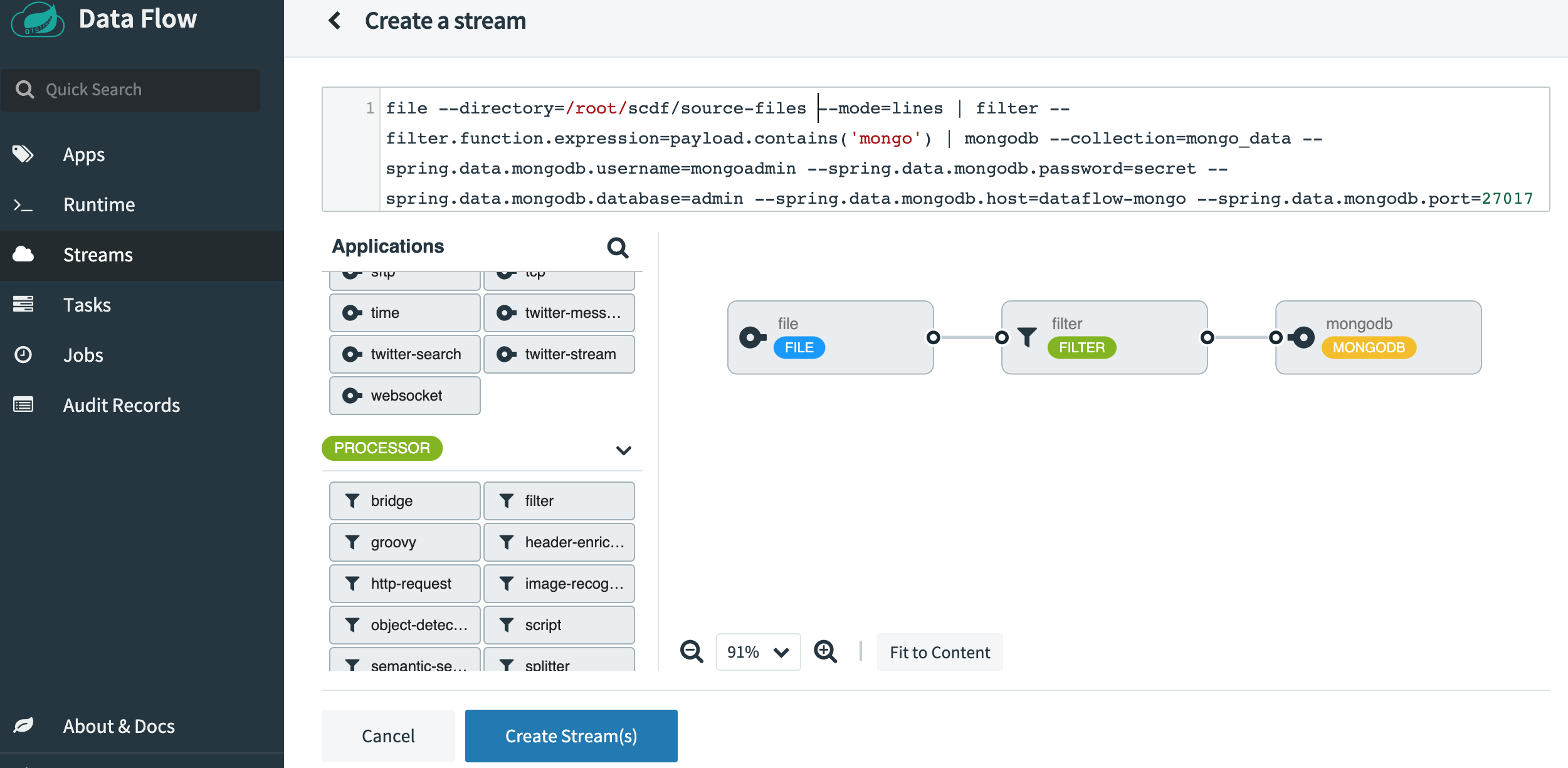
將串流命名為 file-source-filter-mongo,然後按一下「建立串流」。建立後,按一下「部署串流」。接受所有預設選項,然後按一下螢幕底部的「部署串流」。
部署串流後,繼續在調用 Spring Cloud Data Flow docker-compose 腳本的相同目錄中建立一個名為 source-files 的目錄。此目錄已由正在執行其中一個 Spring Cloud Data Flow 組件 (Skipper) 的 docker 容器掛載,並且容器可以看到。確保此 source-files 目錄具有正確的存取層級,尤其是因為 docker 容器將以 root 身分執行應用程式,而您很可能以非 root 使用者身分在您的本機電腦上執行。在 UI 上監看檔案來源應用程式的記錄,以查看是否有任何權限錯誤。如果您看到任何錯誤,請解決這些問題。
準備一個新的終端機工作階段,其中包含 mongo CLI 工具。
docker exec -it dataflow-mongo /bin/sh
# mongo
> use admin
> db.auth(‘mongoadmin’,'secret')
1
> db.createCollection(‘mongo_data’')
{ "ok" : 1 }>
將一些檔案放入 source-files 目錄中,其中包含以下內容。
{"non-sql":"mongo"}
{"sql":"mysql"}
{"document":"mongo"}
{"log":"kafka"}
{"sink":"mongo"}
前往 mongo cli 終端機工作階段。
db.mongo_data.find()
您將看到我們在管線中新增的篩選組件篩選掉了檔案中所有不包含單字 mongo 的條目。您應該看到類似於以下內容的輸出。
{ "_id" : ObjectId("5f4551c470e0373080fcd0b8"), "non-sql" : "mongo" }
{ "_id" : ObjectId("5f4551c470e0373080fcd0b2"), "sink" : "mongo" }
{ "_id" : ObjectId("5f4551c470e0373080fcd0b5"), "document" : "mongo" }
在本部落格中,我們快速瀏覽了檔案供應器及其 Spring Cloud Stream 來源對應項。我們還看到了 MongoDB 消費者和對應的 Spring Cloud Stream 接收器應用程式。我們研究了如何將 function 組件注入到自訂應用程式中。在那之後,我們看到了如何獨立執行檔案來源和 MongoDB 接收器的 Spring Cloud Stream 應用程式。最後,我們深入研究了 Spring Cloud Data Flow,並協調了一個從檔案來源到 MongoDB 接收器的管線,在其過程中篩選掉了一些資料。
本部落格系列將繼續。在接下來的幾週內,我們將研究更多類似於我們在本部落格中描述的情境,但使用不同的 function 和應用程式。