
領先一步
VMware 提供培訓和認證,以加速您的進展。
瞭解更多Spring Data JPA 的便捷功能之一是允許您透過其 @Query 註解外掛自訂 JPA 查詢。
這提供了一些彈性,因為您仍然可以向應用程式的使用者提供排序參數。查看以下範例
interface SampleRepository extends CrudRepository<Employee, Long> {
@Query("select e from Employee e where e.firstName = :firstName")
List<Employee> findCustomEmployees(String firstName, Sort sort);
}
當不僅提供條件 (firstName),而且透過 findCustomEmployees("Alice", Sort.by("lastName")) 提供自訂排序時,Spring Data JPA 會將此自訂查詢轉換為 JPA 查詢,成為以下完整的查詢
select e
from Employee e
where e.firstName = :firstName
order by e.lastName
此外,Spring Data JPA 支援分頁,這需要能夠計算結果集。
過去,隨著越來越複雜的查詢,我們「做對事」並應用「order by」子句以正確指向主要 SELECT 子句的別名值的能力,至少可以說是具有挑戰性的。
用適當的 count() 函數包裝投影也很棘手。想像一下在有子查詢、case 語句和其他深度查詢時執行此操作!
我們很高興宣布發布 HQL 和 JPQL 解析器,這將使您更輕鬆地在 Spring Data JPA 應用程式中自訂查詢。
我們使用 JPA 和 Hibernate 規範,開發了基於 ANTLR 的查詢解析引擎,並使用它們來更正確地應用為您服務所需的自訂。
我們不僅可以找到放置 count() 函數的「正確位置」,還可以獲取主要 FROM 運算式的別名,還可以偵測語意情況。
透過查詢解析器,更容易發現有效與無效的查詢。有時,我們花費更多時間來確定查詢是否正確,然後再弄清楚如何正確處理它。
好消息...它會自動應用。
使用 @Query 註解時,有一個關鍵參數:isNative。這個布林標誌可讓您指示您正在編寫原生 SQL (isNative=true) 還是 JPA 查詢(預設為 isNative=false)。
如果您有 JPA 查詢 (isNative=false) 且 Hibernate 在類別路徑中,它將使用我們新的 HQL 解析器。如果 Hibernate 不在類別路徑中,它將回退到功能較為有限的 JPQL 解析器。(受規範限制,而非我們的實作。)
因此,您只需取得 Spring Data 發布列車的最新快照版本 (Spring Data 3.1 快照) 或取得 Spring Boot 的下一個里程碑版本即可。
還有更多功能要新增。例如,可以有更複雜的別名,例如
select AVG(e.timeToCloseTickets) as avg
from Employee e
當您應用 Sort.by("avg") 時,此類型的查詢不應產生 order by e.avg,而應僅產生 order by avg。我們正在研究新增支援的其他情境。但是有了這些查詢解析器,支援這些情況變得容易得多。
我們還有與查詢解析相關的積壓票證,我們現在可以處理這些票證。
作為額外資訊,如果您想預先檢查自己的自訂查詢,可以使用今天的工具來預覽。
如果您使用 IntelliJ IDEA,則有一個 ANTLR 外掛程式 (https://plugins.jetbrains.com/plugin/7358-antlr-v4),安裝後,您可以執行任何 ANTLR 文法檔案並針對其進行測試。
src/main/antlr4/org/springframework/data/jpa/repository/query/Hql.g4。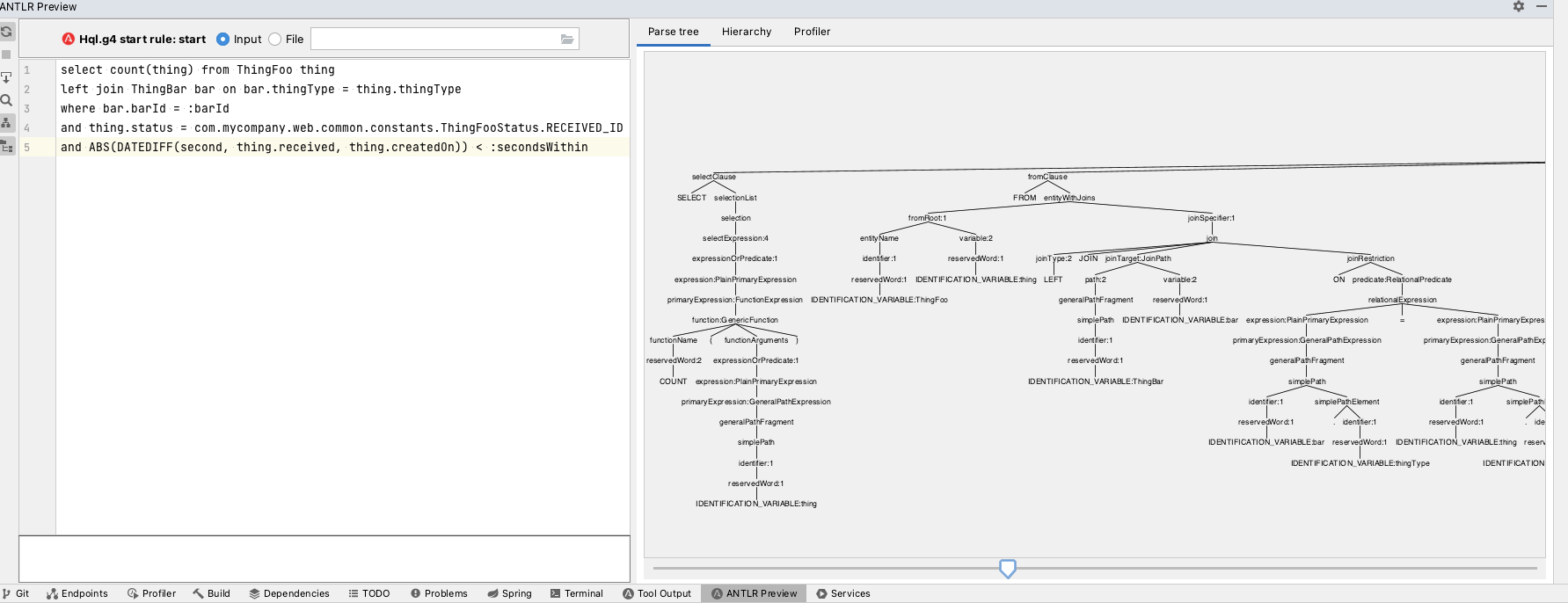
(我們最近要求人們發送他們最瘋狂的 JPA 查詢,而這就是其中之一。乍看之下,查詢是有效的,您甚至可以放大以查看更多內容。)
祝您愉快,--Greg Turnquist