
搶先一步
VMware 提供培訓和認證,以加速您的進度。
了解更多在這篇分為兩部分的部落格文章中,我將討論我對 Spring Petclinic 所做的修改,以納入一個 AI 助理,讓使用者可以使用自然語言與應用程式互動。
Spring Petclinic 是 Spring 生態系統中的主要參考應用程式。根據 GitHub 上的資訊,該儲存庫建立於 2013 年 1 月 9 日。從那時起,它已成為使用 Spring Boot 編寫簡單、開發人員友善程式碼的模型應用程式。截至撰寫本文時,它已獲得超過 7,600 個星標和 23,000 個 fork。
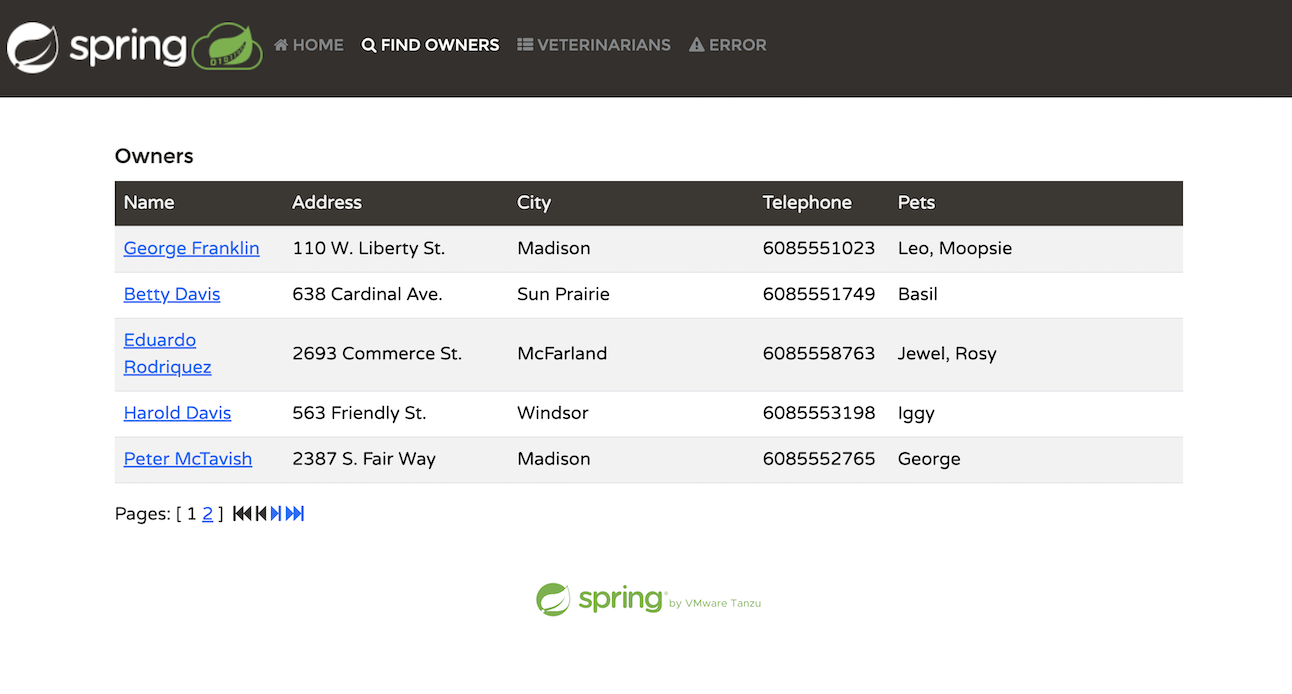
該應用程式模擬獸醫寵物診所的管理系統。在應用程式中,使用者可以執行以下幾項活動
列出寵物主人
新增一位新的主人
為某位主人新增一隻寵物
記錄特定寵物的就診記錄
列出診所中的獸醫
模擬伺服器端錯誤
雖然該應用程式簡單明瞭,但它有效地展示了開發 Spring Boot 應用程式的易用性。
此外,Spring 團隊不斷更新該應用程式,以支援最新版本的 Spring Framework 和 Spring Boot。
Spring Petclinic 是使用 Spring Boot 開發的,截至本發布時,具體版本為 3.3。
前端 UI 是使用 Thymeleaf 建構的。Thymeleaf 的樣板引擎有助於在 HTML 程式碼中進行無縫的後端 API 呼叫,使其易於理解。以下是檢索寵物主人清單的程式碼
<table id="vets" class="table table-striped">
<thead>
<tr>
<th>Name</th>
<th>Specialties</th>
</tr>
</thead>
<tbody>
<tr th:each="vet : ${listVets}">
<td th:text="${vet.firstName + ' ' + vet.lastName}"></td>
<td><span th:each="specialty : ${vet.specialties}"
th:text="${specialty.name + ' '}"/> <span
th:if="${vet.nrOfSpecialties == 0}">none</span></td>
</tr>
</tbody>
</table>
這裡的關鍵行是 ${listVets},它引用 Spring 後端中的一個模型,其中包含要填入的資料。以下是來自 Spring @Controller 的相關程式碼區塊,用於填入此模型
private String addPaginationModel(int page, Page<Vet> paginated, Model model) {
List<Vet> listVets = paginated.getContent();
model.addAttribute("currentPage", page);
model.addAttribute("totalPages", paginated.getTotalPages());
model.addAttribute("totalItems", paginated.getTotalElements());
model.addAttribute("listVets", listVets);
return "vets/vetList";
}
Petclinic 使用 Java Persistence API (JPA) 與資料庫互動。它支援 H2、PostgreSQL 或 MySQL,具體取決於所選的設定檔。資料庫通訊是透過 @Repository 介面進行的,例如 OwnerRepository。以下是介面中其中一個 JPA 查詢的範例
/**
* Returns all the owners from data store
**/
@Query("SELECT owner FROM Owner owner")
@Transactional(readOnly = true)
Page<Owner> findAll(Pageable pageable);
JPA 透過根據命名慣例自動實作方法的預設查詢,從而顯著簡化您的程式碼。它還允許您在需要時使用 @Query 註釋指定 JPQL 查詢。
Spring AI 是 Spring 生態系統中近年來最令人興奮的新專案之一。它使您可以使用熟悉的 Spring 範例和技術與流行的大型語言模型 (LLM) 互動。就像 Spring Data 提供了一個抽象,讓您可以編寫一次程式碼,並將實作委派給提供的 spring-boot-starter 依賴和屬性配置一樣,Spring AI 為 LLM 提供了類似的方法。您只需針對介面編寫一次程式碼,並在執行階段為您的特定實作注入一個 @Bean。
Spring AI 支援所有主要的大型語言模型,包括 OpenAI、Azure 的 OpenAI 實作、Google Gemini、Amazon Bedrock 和 更多。
Spring Petclinic 已經有 10 多年的歷史,最初的設計並未考慮 AI。它是測試將 AI 整合到「舊版」程式碼庫中的經典候選者。在處理向 Spring Petclinic 新增 AI 助理的挑戰時,我必須考慮幾個重要因素。
首先要考量的是確定要實作的 API 類型。Spring AI 提供了各種功能,包括對聊天、影像辨識和產生、音訊轉錄、文字轉語音等的支援。對於 Spring Petclinic 來說,一個熟悉的「聊天機器人」介面最有意義。這將允許診所員工以自然語言與系統溝通,從而簡化他們的互動,而無需瀏覽 UI 標籤和表單。我也需要嵌入功能,這將在本文稍後用於檢索增強產生 (RAG)。

與 AI 助理的可能互動可能包括
您如何協助我?
請列出到我們診所就診的主人。
哪些獸醫專精於放射科?
是否有一個名叫 Betty 的寵物主人?
哪些主人養狗?
為 Betty 新增一隻狗;它的名字是 Moopsie。
這些範例說明了 AI 可以處理的查詢範圍。LLM 的優勢在於它們能夠理解自然語言並提供有意義的回應。
科技界目前正在經歷一場大型語言模型 (LLM) 的淘金熱,每隔幾天就會出現新的模型,每個模型都提供增強的功能、更大的上下文視窗和先進的功能,例如改進的推理能力。
一些流行的大型語言模型包括
OpenAI 及其基於 Azure 的服務 Azure OpenAI
Google Gemini
Amazon Bedrock,一種受管的 AWS 服務,可以執行各種 LLM,包括 Anthropic 和 Titan
Llama 3.1,以及許多其他透過 Hugging Face 提供的開源 LLM
對於我們的 Petclinic 應用程式,我需要一個在聊天功能方面表現出色、可以根據我的應用程式的特定需求進行量身定制並且支援函數呼叫的模型(稍後會詳細介紹!)。
Spring AI 的一大優勢在於能輕鬆地使用各種 LLM 進行 A/B 測試。您只需變更依賴項並更新一些屬性。我測試了幾個模型,包括我在本地執行的 Llama 3.1。最終,我認為 OpenAI 仍然是這個領域的領導者,因為它提供了最自然流暢的互動,同時避免了其他 LLM 常見的缺陷。
以下是一個基本範例:當向由 OpenAI 提供支援的模型打招呼時,回應如下
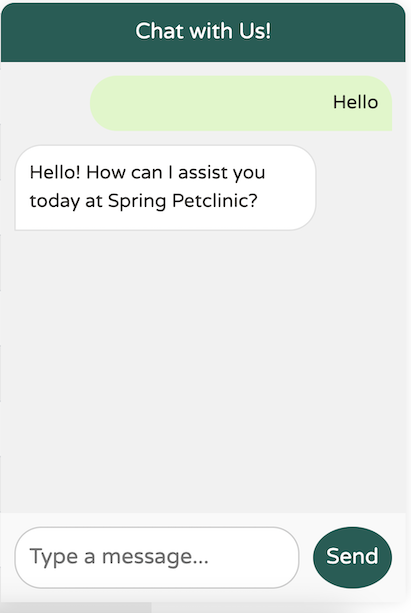
完美。正是我想要的。簡單、簡潔、專業且使用者友善。
以下是使用 Llama3.1 的結果
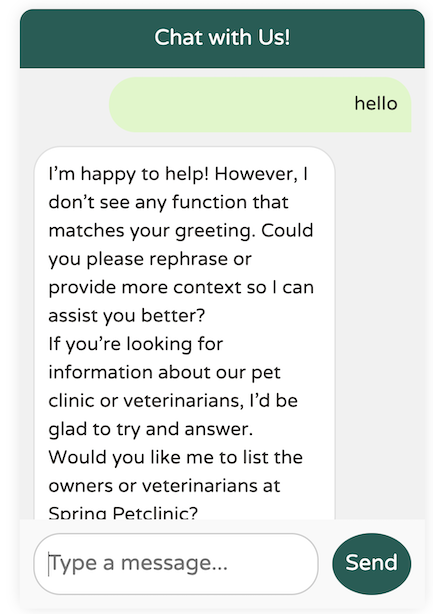
您懂了吧。還沒到位。
設定所需的 LLM 提供者很簡單 - 只需在 pom.xml (或 build.gradle) 中設定其依賴項,並在 application.yaml 或 application.properties 中提供必要的配置屬性
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-azure-openai-spring-boot-starter</artifactId>
</dependency>
在這裡,我選擇了 Azure 的 OpenAI 實作,但我可以透過變更依賴項輕鬆切換到 Sam Altman 的 OpenAI
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
由於我使用的是公開託管的 LLM 提供者,因此我需要提供 URL 和 API 金鑰才能存取 LLM。這可以在 application.yaml 中配置
spring:
ai:
#These parameters apply when using the spring-ai-azure-openai-spring-boot-starter dependency:
azure:
openai:
api-key: "the-api-key"
endpoint: "https://the-url/"
chat:
options:
deployment-name: "gpt-4o"
#These parameters apply when using the spring-ai-openai-spring-boot-starter dependency:
openai:
api-key: ""
endpoint: ""
chat:
options:
deployment-name: "gpt-4o"
我們的目標是建立一個類似 WhatsApp/iMessage 的聊天用戶端,並將其整合到 Spring Petclinic 的現有 UI 中。前端 UI 將呼叫後端 API 端點,該端點接受字串作為輸入並傳回字串作為輸出。對話將開放給使用者可能有的任何問題,如果我們無法協助處理特定請求,我們將提供適當的回應。
以下是在類別 PetclinicChatClient 中針對聊天端點的實作
@PostMapping("/chatclient")
public String exchange(@RequestBody String query) {
//All chatbot messages go through this endpoint and are passed to the LLM
return
this.chatClient
.prompt()
.user(
u ->
u.text(query)
)
.call()
.content();
}
API 接受字串查詢,並將其作為使用者文字傳遞給 Spring AI ChatClient bean。ChatClient 是 Spring AI 提供的一個 Spring Bean,用於管理將使用者文字傳送到 LLM 並在 content() 中傳回結果。
所有 Spring AI 程式碼都在名為
openai的特定@Profile下運作。當使用預設設定檔或任何其他設定檔時,會執行另一個類別PetclinicDisabledChatClient。此停用的設定檔只會傳回一條訊息,指出聊天不可用。
我們的實作主要將職責委派給 ChatClient。但是我們如何建立 ChatClient bean 本身呢?有幾個可配置的選項會影響使用者體驗。讓我們逐一探索它們,並檢查它們對最終應用程式的影響
以下是一個簡單的、未經修改的 ChatClient bean 定義
public PetclinicChatClient(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
在這裡,我們只是根據相依性中目前可用的 Spring AI 啟動器,從建構器請求一個 ChatClient 的實例。雖然此設定有效,但我們的聊天用戶端缺乏對 Petclinic 網域或其服務的任何了解
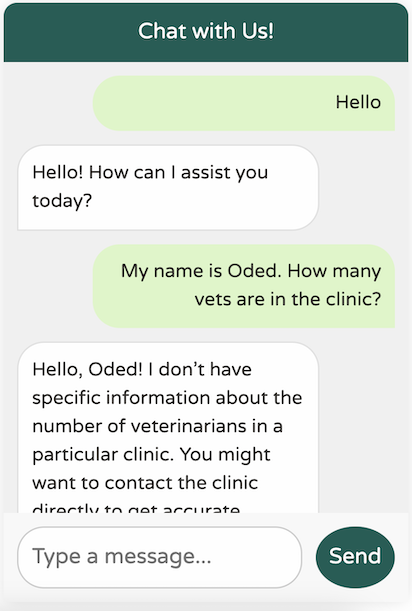
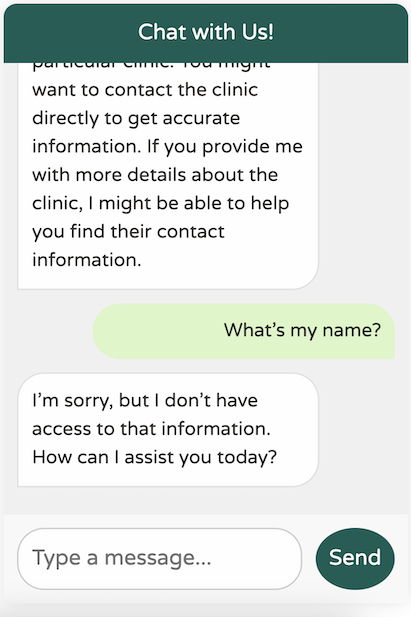
它當然很有禮貌,但它缺乏對我們業務領域的任何理解。此外,它似乎患有嚴重的失憶症——它甚至不記得我從上一條訊息中的名字!
當我查看這篇文章時,我意識到我沒有遵循我的好朋友和同事 Josh Long 的建議。我可能應該對我們新的 AI 霸主更有禮貌!
您可能已經習慣了 ChatGPT 出色的記憶力,這讓它感覺很健談。然而,實際上,LLM API 是完全無狀態的,並且不會保留您傳送的任何過去訊息。這就是為什麼 API 這麼快就忘記了我的名字。
您可能想知道 ChatGPT 如何保持對話上下文。答案很簡單:ChatGPT 會將過去的訊息作為內容與每條新訊息一起傳送。每次您傳送新訊息時,它都會包含先前的對話供模型參考。雖然這看起來可能很浪費,但這就是系統的運作方式。這也是為什麼更大的 token 視窗變得越來越重要的原因——使用者期望回顧幾天前的對話,並從他們離開的地方繼續。
讓我們在我們的應用程式中實作類似的「聊天記憶」功能。幸運的是,Spring AI 提供了一個開箱即用的 Advisor 來幫助實現這一點。您可以將 Advisor 視為在呼叫 LLM 之前運行的 hooks。將它們視為類似於 Aspect-Oriented Programming advice 會很有幫助,即使它們不是以這種方式實作的。
以下是我們更新後的程式碼
public PetclinicChatClient(ChatClient.Builder builder, ChatMemory chatMemory) {
// @formatter:off
this.chatClient = builder
.defaultAdvisors(
// Chat memory helps us keep context when using the chatbot for up to 10 previous messages.
new MessageChatMemoryAdvisor(chatMemory, DEFAULT_CHAT_MEMORY_CONVERSATION_ID, 10), // CHAT MEMORY
new SimpleLoggerAdvisor()
)
.build();
}
在此更新後的程式碼中,我們新增了 MessageChatMemoryAdvisor,它會自動將最後 10 條訊息鏈接到任何新的傳出訊息中,幫助 LLM 了解上下文。
我們還包括了一個開箱即用的 SimpleLoggerAdvisor,它會將來回 LLM 的請求和回應記錄下來。
結果

我們新的聊天機器人具有顯著更好的記憶力!
然而,它仍然不太清楚我們在這裡真正做什麼
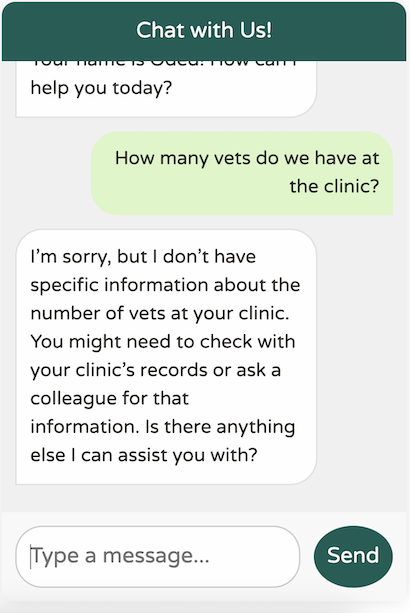
對於通用的世界知識 LLM 來說,這個回應還不錯。然而,我們的診所非常特定於領域,具有特定的使用案例。此外,我們的聊天機器人應僅專注於協助我們處理診所事務。例如,它不應該嘗試回答這樣的問題

如果我們允許我們的聊天機器人回答任何問題,使用者可能會開始將其用作 ChatGPT 等服務的免費替代方案,以存取更先進的模型,例如 GPT-4。顯然,我們需要教導我們的 LLM「模仿」特定的服務提供者。我們的 LLM 應僅專注於協助處理 Spring Petclinic;它應該了解獸醫、主人、寵物和就診——僅此而已。
Spring AI 也為此提供了一個解決方案。大多數 LLM 區分使用者文字(我們傳送的聊天訊息)和系統文字,後者是一般文字,用於指示 LLM 以特定方式運作。讓我們將系統文字新增到我們的聊天用戶端
public PetclinicChatClient(ChatClient.Builder builder, ChatMemory chatMemory) {
// @formatter:off
this.chatClient = builder
.defaultSystem("""
You are a friendly AI assistant designed to help with the management of a veterinarian pet clinic called Spring Petclinic.
Your job is to answer questions about the existing veterinarians and to perform actions on the user's behalf, mainly around
veterinarians, pet owners, their pets and their owner's visits.
You are required to answer an a professional manner. If you don't know the answer, politely tell the user
you don't know the answer, then ask the user a followup qusetion to try and clarify the question they are asking.
If you do know the answer, provide the answer but do not provide any additional helpful followup questions.
When dealing with vets, if the user is unsure about the returned results, explain that there may be additional data that was not returned.
Only if the user is asking about the total number of all vets, answer that there are a lot and ask for some additional criteria. For owners, pets or visits - answer the correct data.
""")
.defaultAdvisors(
// Chat memory helps us keep context when using the chatbot for up to 10 previous messages.
new MessageChatMemoryAdvisor(chatMemory, DEFAULT_CHAT_MEMORY_CONVERSATION_ID, 10), // CHAT MEMORY
new LoggingAdvisor()
)
.build();
}
這是一個相當冗長的預設系統提示!但請相信我,這是必要的。事實上,這可能還不夠,並且隨著系統的使用頻率越來越高,我可能需要新增更多上下文。提示工程的過程涉及設計和最佳化輸入提示,以針對給定的使用案例引出特定、準確的回應。
LLM 非常健談;它們喜歡以自然語言回應。這種趨勢使得以 JSON 等格式取得機器對機器回應變得具有挑戰性。為了解決這個問題,Spring AI 提供了一組專用於結構化輸出的功能,稱為結構化輸出轉換器。Spring 團隊必須找出最佳的提示工程技術,以確保 LLM 在回應時不會出現不必要的「健談」。以下是 Spring AI MapOutputConverter bean 中的一個範例
@Override
public String getFormat() {
String raw = """
Your response should be in JSON format.
The data structure for the JSON should match this Java class: %s
Do not include any explanations, only provide a RFC8259 compliant JSON response following this format without deviation.
Remove the ```json markdown surrounding the output including the trailing "```".
""";
return String.format(raw, HashMap.class.getName());
}
每當 LLM 的回應需要採用 JSON 格式時,Spring AI 都會將整個字串附加到請求中,敦促 LLM 遵循。
最近,在該領域取得了一些積極的進展,特別是 OpenAI 的結構化輸出計劃。與此類進展通常情況一樣,Spring AI 全心全意地擁抱了它。
現在,回到我們的聊天機器人——讓我們看看它的表現如何!
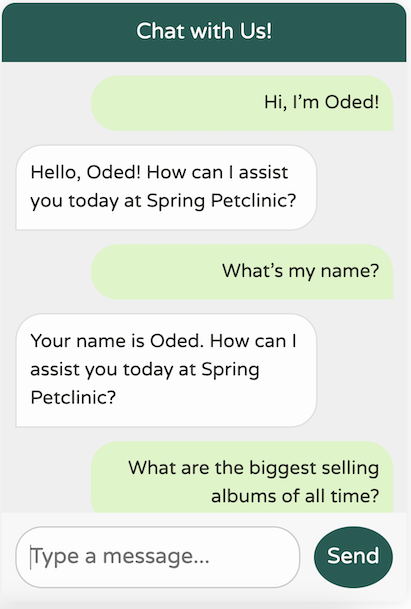
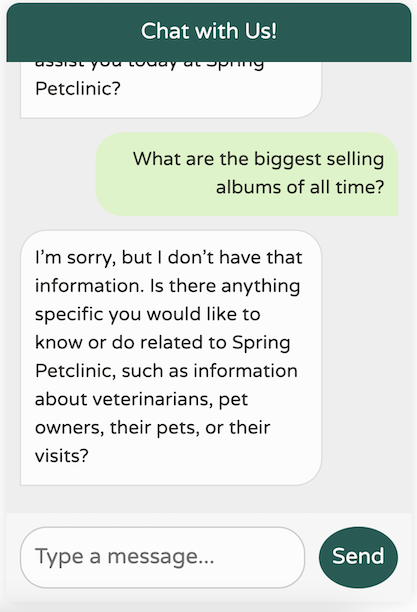
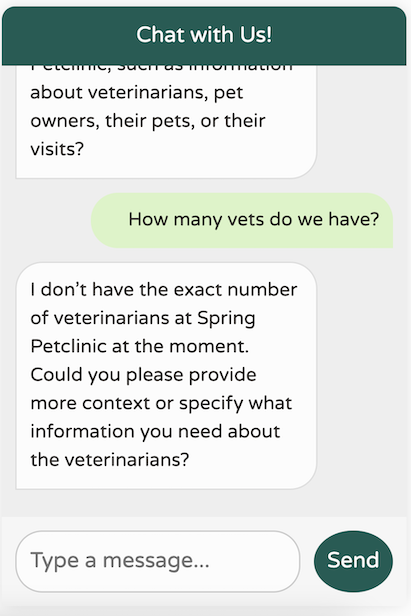
這是一個顯著的改進!我們現在有一個聊天機器人,它已針對我們的網域進行調整,專注於我們的特定使用案例,記得最後 10 條訊息,不提供任何不相關的世界知識,並且避免產生它沒有的數據。此外,我們的日誌會列印我們對 LLM 進行的呼叫,使除錯變得更加容易。
2024-09-21T21:55:08.888+03:00 DEBUG 85824 --- [nio-8080-exec-5] o.s.a.c.c.advisor.SimpleLoggerAdvisor : request: AdvisedRequest[chatModel=org.springframework.ai.azure.openai.AzureOpenAiChatModel@5cdd90c4, userText="Hi! My name is Oded.", systemText=You are a friendly AI assistant designed to help with the management of a veterinarian pet clinic called Spring Petclinic.
Your job is to answer questions about the existing veterinarians and to perform actions on the user's behalf, mainly around
veterinarians, pet owners, their pets and their owner's visits.
You are required to answer an a professional manner. If you don't know the answer, politely tell the user
you don't know the answer, then ask the user a followup qusetion to try and clarify the question they are asking.
If you do know the answer, provide the answer but do not provide any additional helpful followup questions.
When dealing with vets, if the user is unsure about the returned results, explain that there may be additional data that was not returned.
Only if the user is asking about the total number of all vets, answer that there are a lot and ask for some additional criteria. For owners, pets or visits - answer the correct data.
, chatOptions=org.springframework.ai.azure.openai.AzureOpenAiChatOptions@c4c74d4, media=[], functionNames=[], functionCallbacks=[], messages=[], userParams={}, systemParams={}, advisors=[org.springframework.ai.chat.client.advisor.observation.ObservableRequestResponseAdvisor@1e561f7, org.springframework.ai.chat.client.advisor.observation.ObservableRequestResponseAdvisor@79348b22], advisorParams={}]
2024-09-21T21:55:10.594+03:00 DEBUG 85824 --- [nio-8080-exec-5] o.s.a.c.c.advisor.SimpleLoggerAdvisor : response: {"result":{"metadata":{"contentFilterMetadata":{"sexual":{"severity":"safe","filtered":false},"violence":{"severity":"safe","filtered":false},"hate":{"severity":"safe","filtered":false},"selfHarm":{"severity":"safe","filtered":false},"profanity":null,"customBlocklists":null,"error":null,"protectedMaterialText":null,"protectedMaterialCode":null},"finishReason":"stop"},"output":{"messageType":"ASSISTANT","metadata":{"finishReason":"stop","choiceIndex":0,"id":"chatcmpl-A9zY6UlOdkTCrFVga9hbzT0LRRDO4","messageType":"ASSISTANT"},"toolCalls":[],"content":"Hello, Oded! How can I assist you today at Spring Petclinic?"}},"metadata":{"id":"chatcmpl-A9zY6UlOdkTCrFVga9hbzT0LRRDO4","model":"gpt-4o-2024-05-13","rateLimit":{"requestsLimit":0,"requestsRemaining":0,"requestsReset":0.0,"tokensRemaining":0,"tokensLimit":0,"tokensReset":0.0},"usage":{"promptTokens":633,"generationTokens":17,"totalTokens":650},"promptMetadata":[{"contentFilterMetadata":{"sexual":null,"violence":null,"hate":null,"selfHarm":null,"profanity":null,"customBlocklists":null,"error":null,"jailbreak":null,"indirectAttack":null},"promptIndex":0}],"empty":false},"results":[{"metadata":{"contentFilterMetadata":{"sexual":{"severity":"safe","filtered":false},"violence":{"severity":"safe","filtered":false},"hate":{"severity":"safe","filtered":false},"selfHarm":{"severity":"safe","filtered":false},"profanity":null,"customBlocklists":null,"error":null,"protectedMaterialText":null,"protectedMaterialCode":null},"finishReason":"stop"},"output":{"messageType":"ASSISTANT","metadata":{"finishReason":"stop","choiceIndex":0,"id":"chatcmpl-A9zY6UlOdkTCrFVga9hbzT0LRRDO4","messageType":"ASSISTANT"},"toolCalls":[],"content":"Hello, Oded! How can I assist you today at Spring Petclinic?"}}]}
我們的聊天機器人表現如預期,但目前缺乏有關我們應用程式中數據的知識。讓我們關注 Spring Petclinic 支援的核心功能,並將它們映射到我們可能想要使用 Spring AI 啟用的功能
在「主人」標籤頁中,我們可以透過姓氏搜尋主人,或直接列出所有主人。我們可以取得每位主人的詳細資訊,包括他們的姓名,以及他們所擁有的寵物及其類型。
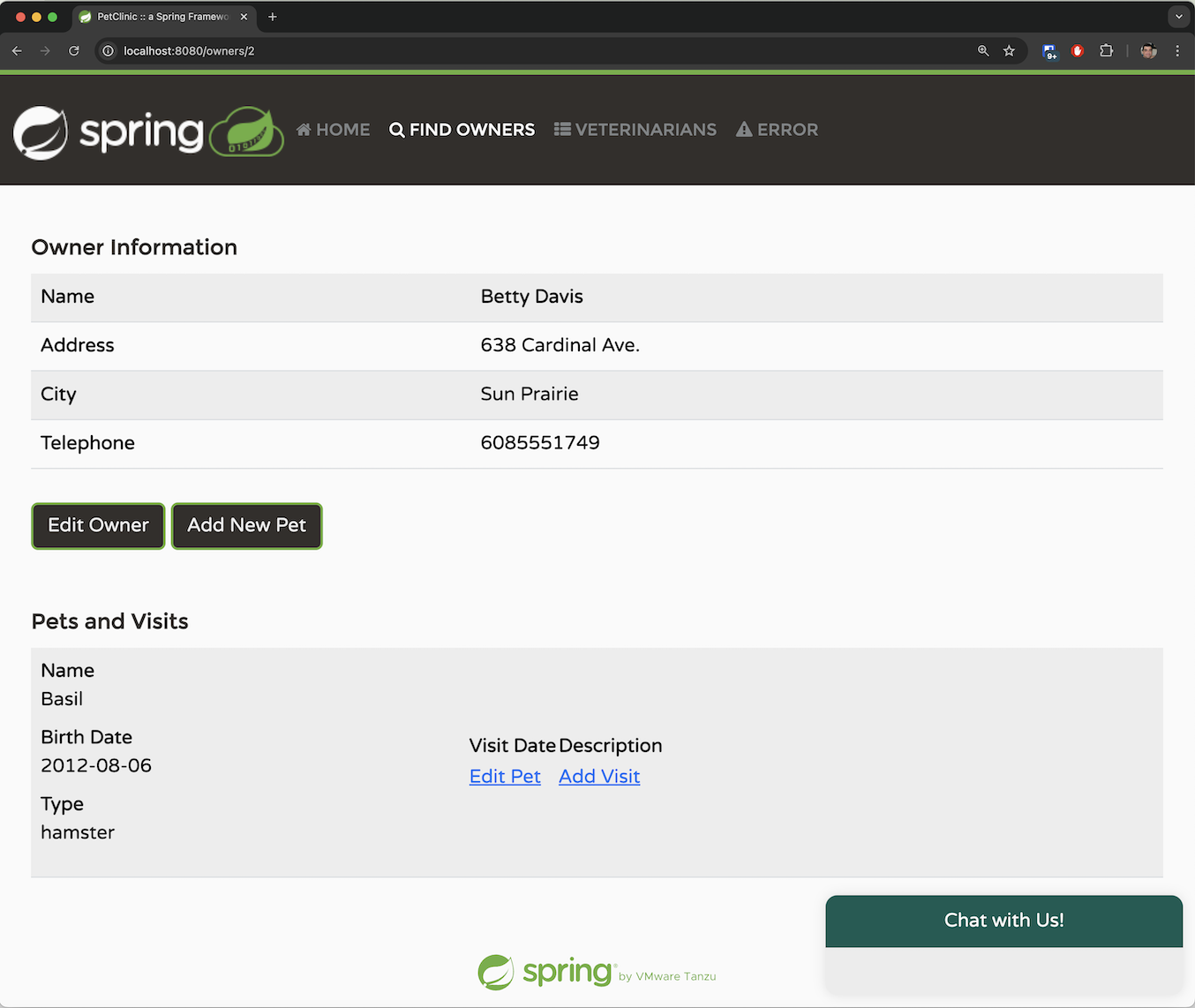
此應用程式允許您透過提供系統要求的必要參數來新增一位新主人。一位主人必須擁有姓名、地址和一組 10 位數的電話號碼。
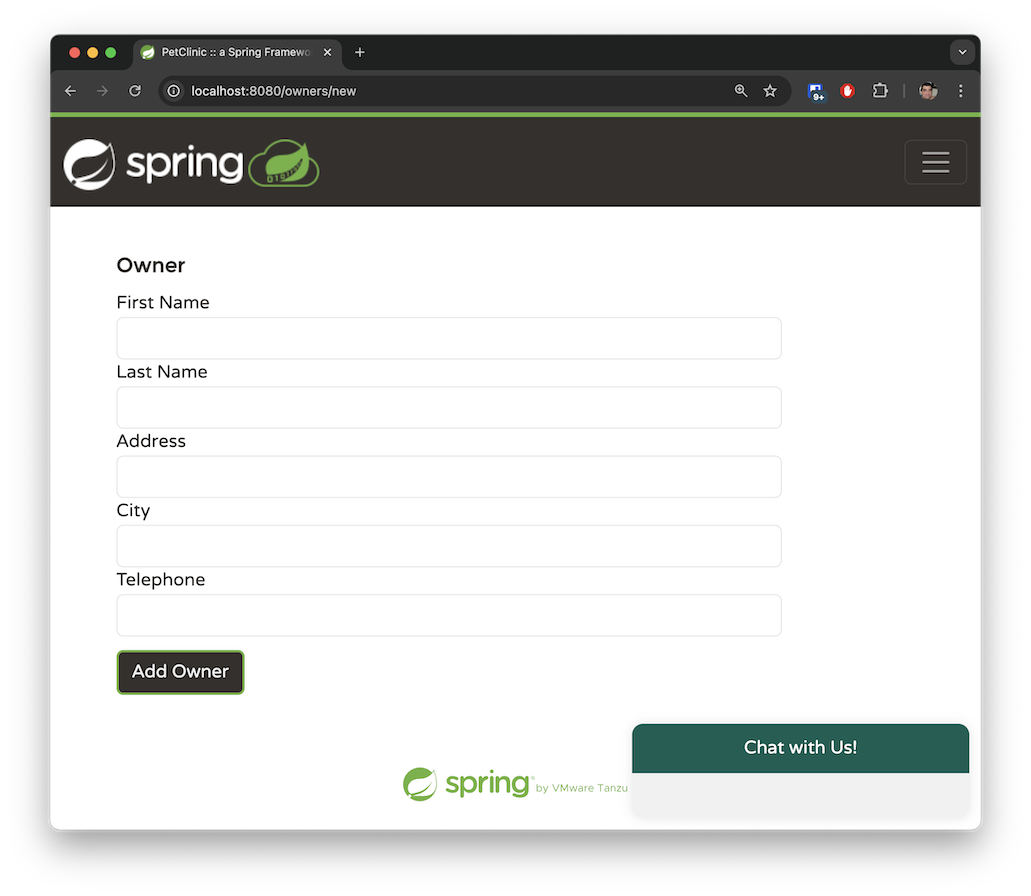
一位主人可以擁有多隻寵物。寵物類型僅限於以下幾種:貓、狗、蜥蜴、蛇、鳥或倉鼠。
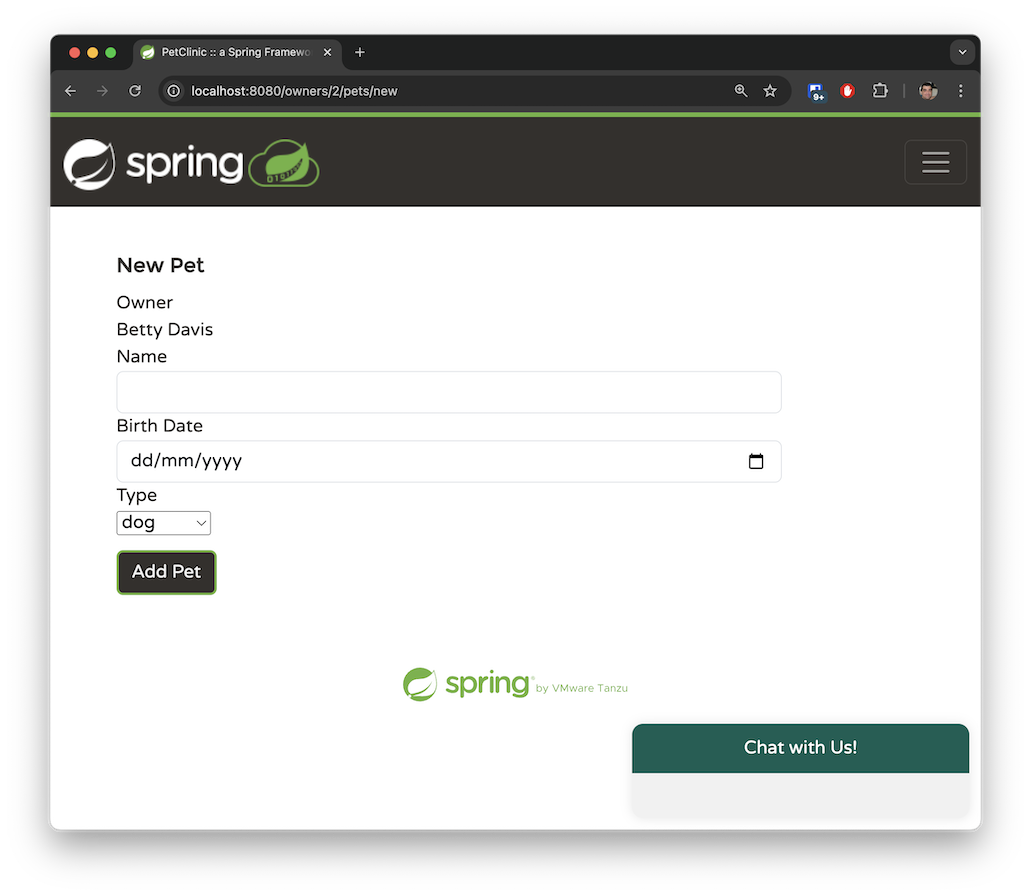
「獸醫」標籤頁會以分頁檢視顯示可用的獸醫及其專長。目前此標籤頁沒有搜尋功能。雖然 Spring Petclinic 的 main 分支只有少數獸醫,但我在 spring-ai 分支中產生了數百個模擬獸醫,以模擬處理大量資料的應用程式。稍後,我們將探討如何使用檢索增強生成 (RAG) 來管理如此龐大的資料集。
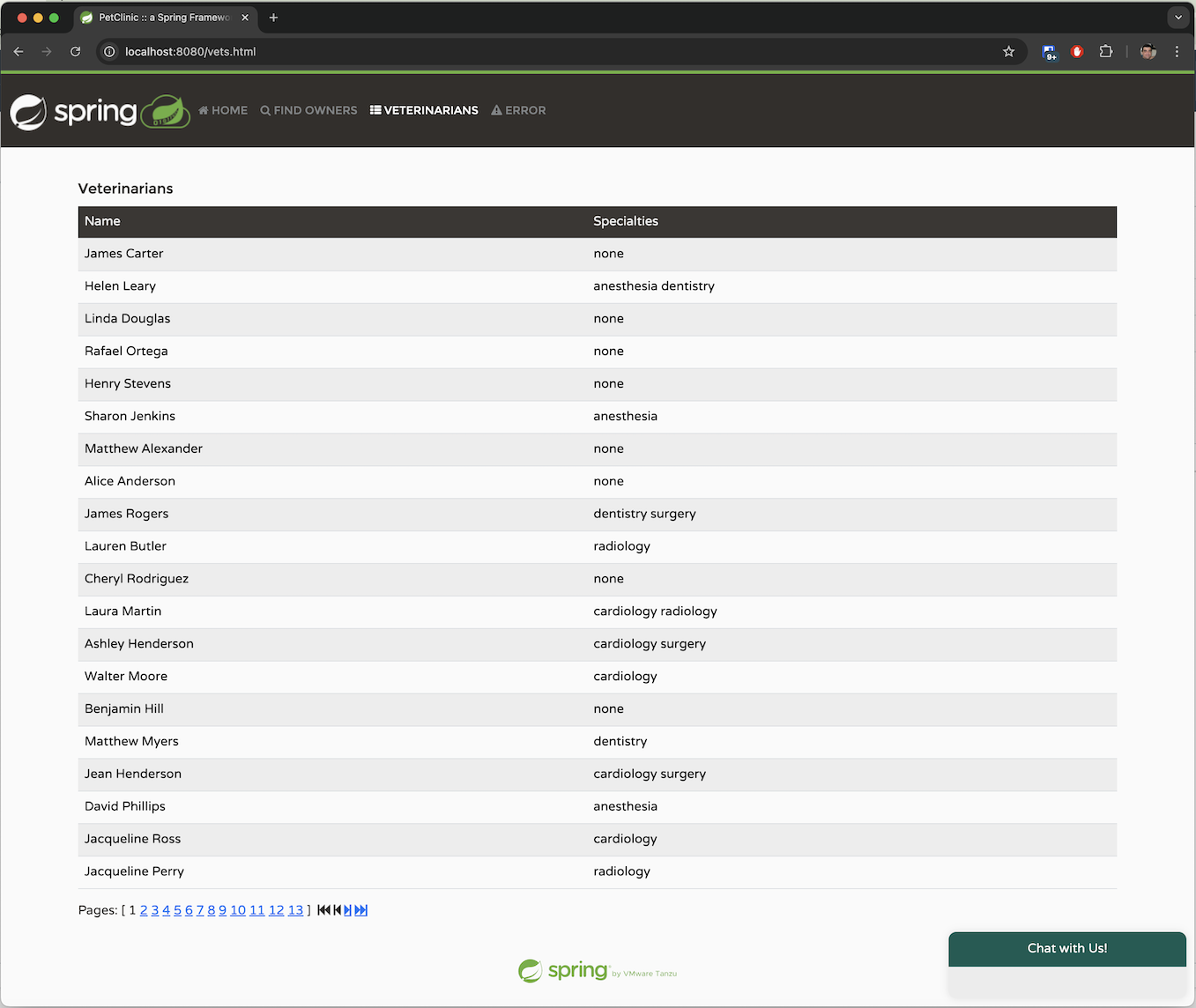
這些是我們可以在系統中執行的主要操作。我們已將應用程式對應到其基本功能,並且希望 OpenAI 推斷與這些操作對應的自然語言請求。
在前一節中,我們描述了四種不同的函式。現在,讓我們透過指定特定的 java.util.function.Function beans,將它們對應到我們可以與 Spring AI 一起使用的函式。
以下 java.util.function.Function 負責傳回 Spring Petclinic 中的主人清單
@Configuration
@Profile("openai")
class AIFunctionConfiguration {
// The @Description annotation helps the model understand when to call the function
@Bean
@Description("List the owners that the pet clinic has")
public Function<OwnerRequest, OwnersResponse> listOwners(AIDataProvider petclinicAiProvider) {
return request -> {
return petclinicAiProvider.getAllOwners();
};
}
}
record OwnerRequest(Owner owner) {
};
record OwnersResponse(List<Owner> owners) {
};
我們正在 openai 設定檔中建立一個 @Configuration 類別,並在其中註冊一個標準的 Spring @Bean。
此 bean 必須傳回一個 java.util.function.Function。
我們使用 Spring 的 @Description 註解來說明此函式的作用。值得注意的是,Spring AI 會將此描述傳遞給 LLM,以協助它判斷何時呼叫此特定函式。
此函式接受一個 OwnerRequest 記錄,其中包含現有的 Spring Petclinic Owner 實體類別。這示範了 Spring AI 如何利用您已在應用程式中開發的元件,而無需完全重寫。
OpenAI 會決定何時使用代表 OwnerRequest 記錄的 JSON 物件來叫用函式。Spring AI 會自動將此 JSON 轉換為 OwnerRequest 物件並執行該函式。傳回回應後,Spring AI 會將產生的 OwnerResponse 記錄 (其中包含一個 List<Owner>) 轉換回 JSON 格式,以供 OpenAI 處理。當 OpenAI 收到回應時,它會以自然語言撰寫回覆給使用者。
此函式呼叫實作實際邏輯的 AIDataProvider @Service bean。在我們這個簡單的用例中,此函式僅使用 JPA 查詢資料
public OwnersResponse getAllOwners() {
Pageable pageable = PageRequest.of(0, 100);
Page<Owner> ownerPage = ownerRepository.findAll(pageable);
return new OwnersResponse(ownerPage.getContent());
}
Spring Petclinic 的現有舊程式碼會傳回分頁資料,以保持回應大小的可管理性,並促進 UI 中分頁檢視的處理。在我們的例子中,我們預期主人的總數相對較少,並且 OpenAI 應該能夠在單個請求中處理此類流量。因此,我們在單個 JPA 請求中傳回前 100 位主人。
您可能會認為這種方法並非最佳,而在真實世界的應用程式中,您的想法是正確的。如果資料量很大,這種方法會效率不彰 - 我們系統中可能會有超過 100 位主人。對於這種情況,我們需要實作不同的模式,正如我們將在 listVets 函式中探討的那樣。但是,對於我們的示範用例,我們可以假設我們的系統包含少於 100 位主人。
讓我們使用一個真實的範例以及 SimpleLoggerAdvisor 來觀察幕後發生的事情
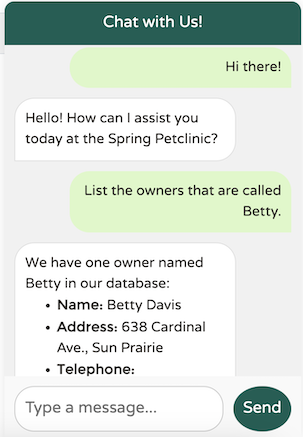
這裡發生了什麼事?讓我們檢閱 SimpleLoggerAdvisor 日誌中的輸出以進行調查
request:
AdvisedRequest[chatModel=org.springframework.ai.azure.openai.AzureOpenAiChatModel@18e69455,
userText=
"List the owners that are called Betty.",
systemText=You are a friendly AI assistant designed to help with the management of a veterinarian pet clinic called Spring Petclinic.
Your job...
chatOptions=org.springframework.ai.azure.openai.AzureOpenAiChatOptions@3d6f2674,
media=[],
functionNames=[],
functionCallbacks=[],
messages=[UserMessage{content='"Hi there!"',
properties={messageType=USER},
messageType=USER},
AssistantMessage [messageType=ASSISTANT, toolCalls=[],
textContent=Hello! How can I assist you today at Spring Petclinic?,
metadata={choiceIndex=0, finishReason=stop, id=chatcmpl-A99D20Ql0HbrpxYc0LIkWZZLVIAKv,
messageType=ASSISTANT}]],
userParams={}, systemParams={}, advisors=[org.springframework.ai.chat.client.advisor.observation.ObservableRequestResponseAdvisor@1d04fb8f,
org.springframework.ai.chat.client.advisor.observation.ObservableRequestResponseAdvisor@2fab47ce], advisorParams={}]
此請求包含有關傳送給 LLM 之有趣資料,包括使用者文字、歷史訊息、代表目前聊天會話的 ID、要觸發的 advisor 清單以及系統文字。
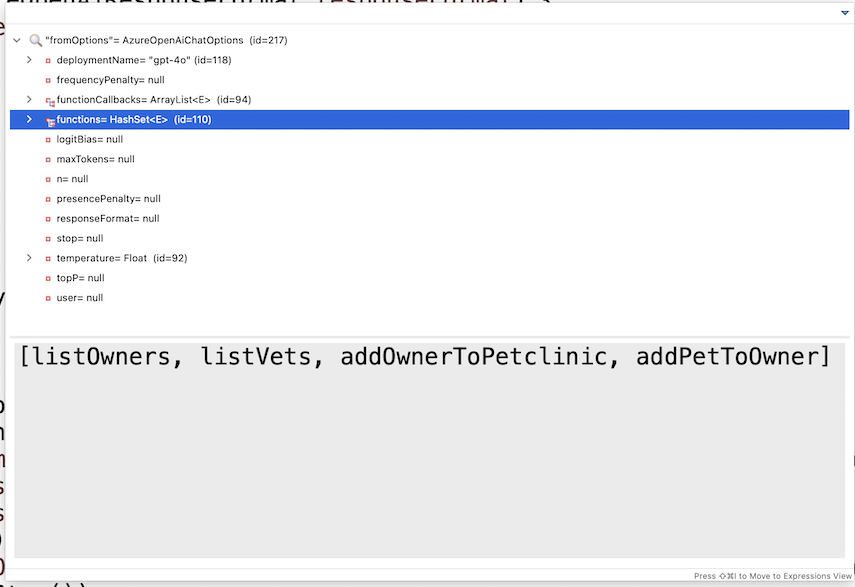
您可能想知道日誌請求中的函式在哪裡。這些函式未明確記錄;它們封裝在 AzureOpenAiChatOptions 的內容中。在偵錯模式下檢查該物件會顯示模型可用的函式清單
OpenAI 會處理該請求,確定它需要來自主人清單的資料,並傳回一個 JSON 回覆給 Spring AI,要求從 listOwners 函式取得額外資訊。然後,Spring AI 會使用從 OpenAI 提供的 OwnersRequest 物件來叫用該函式,並將回應傳送回 OpenAI,同時維護對話 ID 以協助在無狀態連線上保持工作階段連續性。OpenAI 會根據提供的額外資料產生最終回應。讓我們檢閱記錄的該回應
response: {
"result": {
"metadata": {
"finishReason": "stop",
"contentFilterMetadata": {
"sexual": {
"severity": "safe",
"filtered": false
},
"violence": {
"severity": "safe",
"filtered": false
},
"hate": {
"severity": "safe",
"filtered": false
},
"selfHarm": {
"severity": "safe",
"filtered": false
},
"profanity": null,
"customBlocklists": null,
"error": null,
"protectedMaterialText": null,
"protectedMaterialCode": null
}
},
"output": {
"messageType": "ASSISTANT",
"metadata": {
"choiceIndex": 0,
"finishReason": "stop",
"id": "chatcmpl-A9oKTs6162OTut1rkSKPH1hE2R08Y",
"messageType": "ASSISTANT"
},
"toolCalls": [],
"content": "The owner named Betty in our records is:\n\n- **Betty Davis**\n - **Address:** 638 Cardinal Ave., Sun Prairie\n - **Telephone:** 608-555-1749\n - **Pet:** Basil (Hamster), born on 2012-08-06\n\nIf you need any more details or further assistance, please let me know!"
}
},
...
]
}
我們在 content 區段中看到了回應本身。大多數傳回的 JSON 都由元資料組成,例如內容過濾器、正在使用的模型、回應中的聊天 ID 工作階段、消耗的 token 數量、回應完成的方式等等。
這說明了系統如何端對端運作:它從您的瀏覽器開始,到達 Spring 後端,並且涉及 Spring AI 和 LLM 之間的 B2B 乒乓互動,直到將回應傳送回發出初始呼叫的 JavaScript。
現在,讓我們檢閱其餘三個函式。
addPetToOwner 方法特別有趣,因為它展示了模型函式呼叫的強大功能。
當使用者想要將寵物新增至主人時,期望他們輸入寵物類型 ID 是不切實際的。相反地,他們可能會說寵物是「狗」,而不是簡單地提供一個像「2」這樣的數字 ID。
為了協助 LLM 判斷正確的寵物類型,我利用 @Description 註解來提供有關我們需求的提示。由於我們的寵物診所只處理六種類型的寵物,因此這種方法是可管理且有效的
@Bean
@Description("Add a pet with the specified petTypeId, " + "to an owner identified by the ownerId. "
+ "The allowed Pet types IDs are only: " + "1 - cat" + "2 - dog" + "3 - lizard" + "4 - snake" + "5 - bird"
+ "6 - hamster")
public Function<AddPetRequest, AddedPetResponse> addPetToOwner(AIDataProvider petclinicAiProvider) {
return request -> {
return petclinicAiProvider.addPetToOwner(request);
};
}
AddPetRequest 記錄包含自由文字中的寵物類型,反映了使用者通常提供的內容,以及完整的 Pet 實體和參考的 ownerId。
record AddPetRequest(Pet pet, String petType, Integer ownerId) {
};
record AddedPetResponse(Owner owner) {
};
這是業務實作:我們透過其 ID 檢索主人,然後將新寵物新增到其現有的寵物清單中。
public AddedPetResponse addPetToOwner(AddPetRequest request) {
Owner owner = ownerRepository.findById(request.ownerId());
owner.addPet(request.pet());
this.ownerRepository.save(owner);
return new AddedPetResponse(owner);
}
在偵錯本文的流程時,我注意到一個有趣的行為:在某些情況下,請求中的 Pet 實體已經預先填入了正確的寵物類型 ID 和名稱。
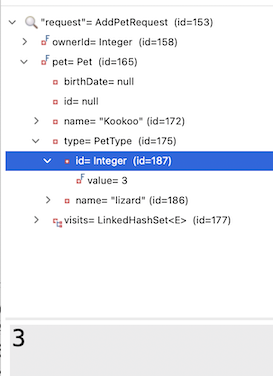
我也注意到我實際上並沒有在我的商業邏輯中使用 petType 字串。Spring AI 是否有可能自行「找出」PetType 名稱與正確 ID 之間的對應關係?
為了驗證這一點,我從請求物件中移除了 petType,並且簡化了 @Description 的描述。
@Bean
@Description("Add a pet with the specified petTypeId, to an owner identified by the ownerId.")
public Function<AddPetRequest, AddedPetResponse> addPetToOwner(AIDataProvider petclinicAiProvider) {
return request -> {
return petclinicAiProvider.addPetToOwner(request);
};
}
record AddPetRequest(Pet pet, Integer ownerId) {
};
record AddedPetResponse(Owner owner) {
};
我發現,在大多數的提示中,LLM 都能出色地自行找出如何執行對應。我最終還是保留了 PR 中的原始描述,因為我注意到有些邊緣情況下,LLM 會難以理解且無法找出相關性。
儘管如此,即使對於 80% 的使用案例來說,這仍然令人印象深刻。這些事情讓 Spring AI 和 LLM 幾乎感覺像魔法一樣。Spring AI 和 OpenAI 之間的互動成功理解了 Pet 的 @Entity 中的 PetType 需要將字串 "lizard" 對應到資料庫中相應的 ID 值。這種無縫整合展現了將傳統程式設計與 AI 功能結合的潛力。
// These are the original insert queries in data.sql
INSERT INTO types VALUES (default, 'cat'); //1
INSERT INTO types VALUES (default, 'dog'); //2
INSERT INTO types VALUES (default, 'lizard'); //3
INSERT INTO types VALUES (default, 'snake'); //4
INSERT INTO types VALUES (default, 'bird'); //5
INSERT INTO types VALUES (default, 'hamster'); //6
@Entity
@Table(name = "pets")
public class Pet extends NamedEntity {
private static final long serialVersionUID = 622048308893169889L;
@Column(name = "birth_date")
@DateTimeFormat(pattern = "yyyy-MM-dd")
private LocalDate birthDate;
@ManyToOne
@JoinColumn(name = "type_id")
private PetType type;
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.EAGER)
@JoinColumn(name = "pet_id")
@OrderBy("visit_date ASC")
private Set<Visit> visits = new LinkedHashSet<>();
即使你在請求中輸入一些錯字,它也能正常運作。在下面的範例中,LLM 識別出我將 "hamster" 拼錯為 "hamstr",更正了請求,並成功地將其與正確的 Pet ID 匹配。
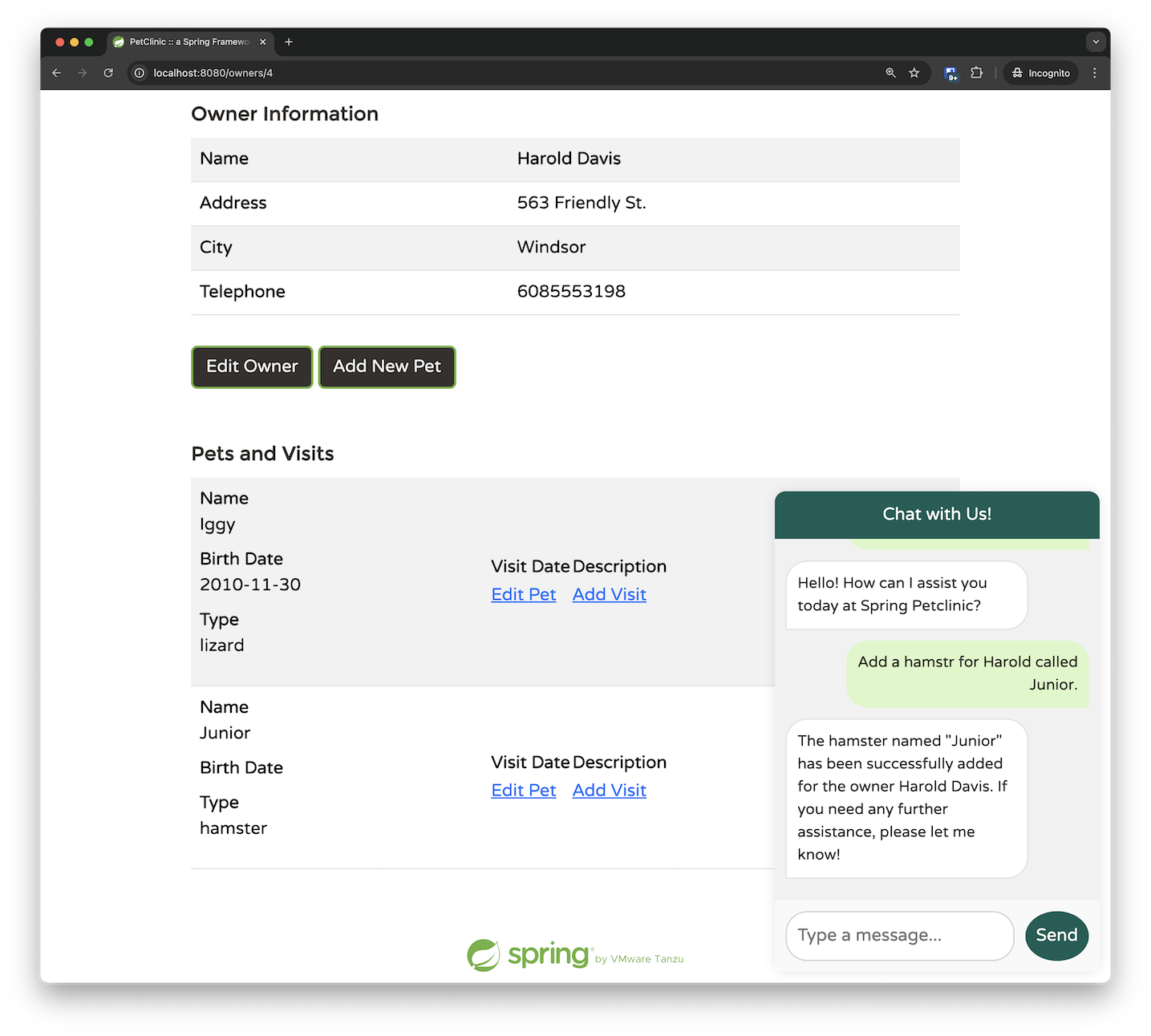
如果你深入挖掘,你會發現事情變得更加令人印象深刻。AddPetRequest 只將 ownerId 作為參數傳遞;我提供了所有者的名字而不是他們的 ID,而 LLM 成功地自行確定了正確的對應關係。這表示 LLM 選擇在調用 addPetToOwner 函數之前,先調用了 listOwners 函數。透過新增一些中斷點,我們可以確認這個行為。最初,我們命中了檢索所有者的中斷點。

只有在返回並處理所有者資料後,我們才會調用 addPetToOwner 函數。

我的結論是:使用 Spring AI,從簡單開始。提供你知道需要的必要資料,並使用簡短精確的 bean 描述。Spring AI 和 LLM 很可能「找出」其餘的部分。只有在出現問題時,你才應該開始向系統新增更多提示。
addOwner 函數相對簡單。它接受一個所有者,並將他/她新增到系統中。但是,在這個範例中,我們可以了解如何使用我們的聊天助手來執行驗證和提出後續問題。
@Bean
@Description("Add a new pet owner to the pet clinic. "
+ "The Owner must include first and last name, "
+ "an address and a 10-digit phone number")
public Function<OwnerRequest, OwnerResponse> addOwnerToPetclinic(AIDataProvider petclinicAiDataProvider) {
return request -> {
return petclinicAiDataProvider.addOwnerToPetclinic(request);
};
}
record OwnerRequest(Owner owner) {
};
record OwnerResponse(Owner owner) {
};
商業邏輯的實作很簡單
public OwnerResponse addOwnerToPetclinic(OwnerRequest ownerRequest) {
ownerRepository.save(ownerRequest.owner());
return new OwnerResponse(ownerRequest.owner());
}
在這裡,我們引導模型,確保 OwnerRequest 中的 Owner 符合某些驗證標準,然後才能新增。具體來說,所有者必須包含名字、姓氏、地址和 10 位數的電話號碼。如果缺少任何這些資訊,模型將提示我們提供必要的詳細資訊,然後才能繼續新增所有者。
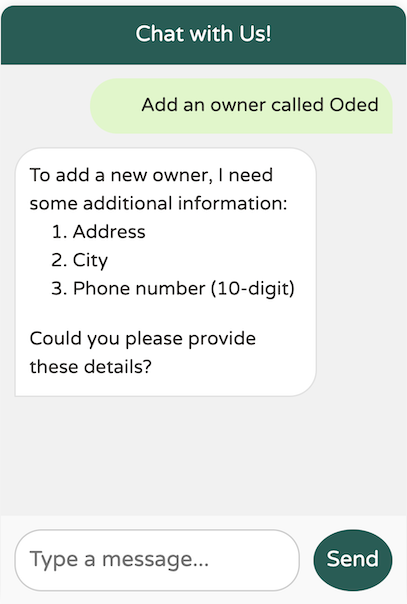
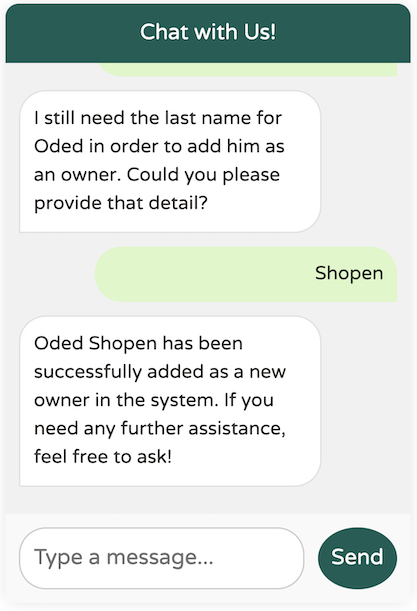
在請求必要的額外資料(例如地址、城市和電話號碼)之前,模型沒有建立新的所有者。但是,我不記得有提供必要的姓氏。它還能正常運作嗎?

我們在模型中發現了一個邊緣情況:它似乎沒有強制要求姓氏,即使 @Description 指定它是強制性的。我們該如何解決這個問題?使用提示工程來救援!
@Bean
@Description("Add a new pet owner to the pet clinic. "
+ "The Owner must include a first name and a last name as two separate words, "
+ "plus an address and a 10-digit phone number")
public Function<OwnerRequest, OwnerResponse> addOwnerToPetclinic(AIDataProvider petclinicAiDataProvider) {
return request -> {
return petclinicAiDataProvider.addOwnerToPetclinic(request);
};
}
透過在我們的描述中新增提示「作為兩個獨立的單字」,模型更清楚地了解了我們的期望,使其能夠正確地強制要求姓氏。
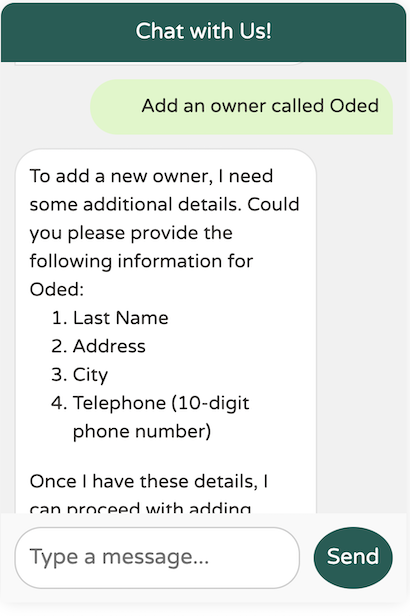
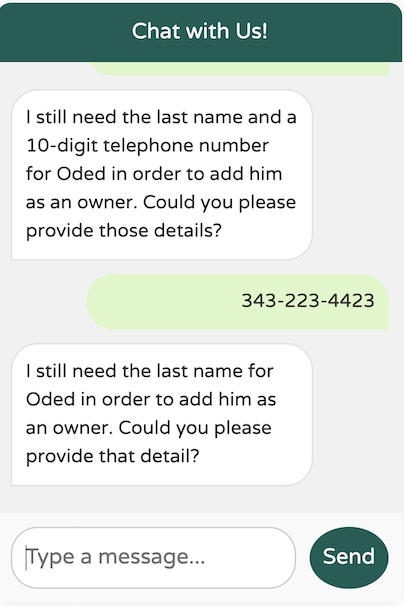
在本文的第一部分中,我們探討了如何利用 Spring AI 來使用大型語言模型。我們建立了一個自訂的 ChatClient,使用了 Function Calling,並針對我們的特定需求改進了提示工程。
在第二部分中,我們將深入探討檢索增強生成 (RAG) 的強大功能,以將模型與大型、特定領域的資料集整合,這些資料集太大而無法放入 Function Calling 方法中。