
領先一步
VMware 提供培訓和認證,以加速您的進程。
了解更多我們很高興宣布 Spring AI 的 1.0.0 Milestone 3 版本發布。
此版本在各個領域帶來了顯著的增強功能和新特性。
此版本對可觀察性堆疊進行了許多改進,特別是對於來自 Chat Model 的串流回應。非常感謝 Thomas Vitale 和 Dariusz Jedrzejczyk 在此領域提供的所有協助!
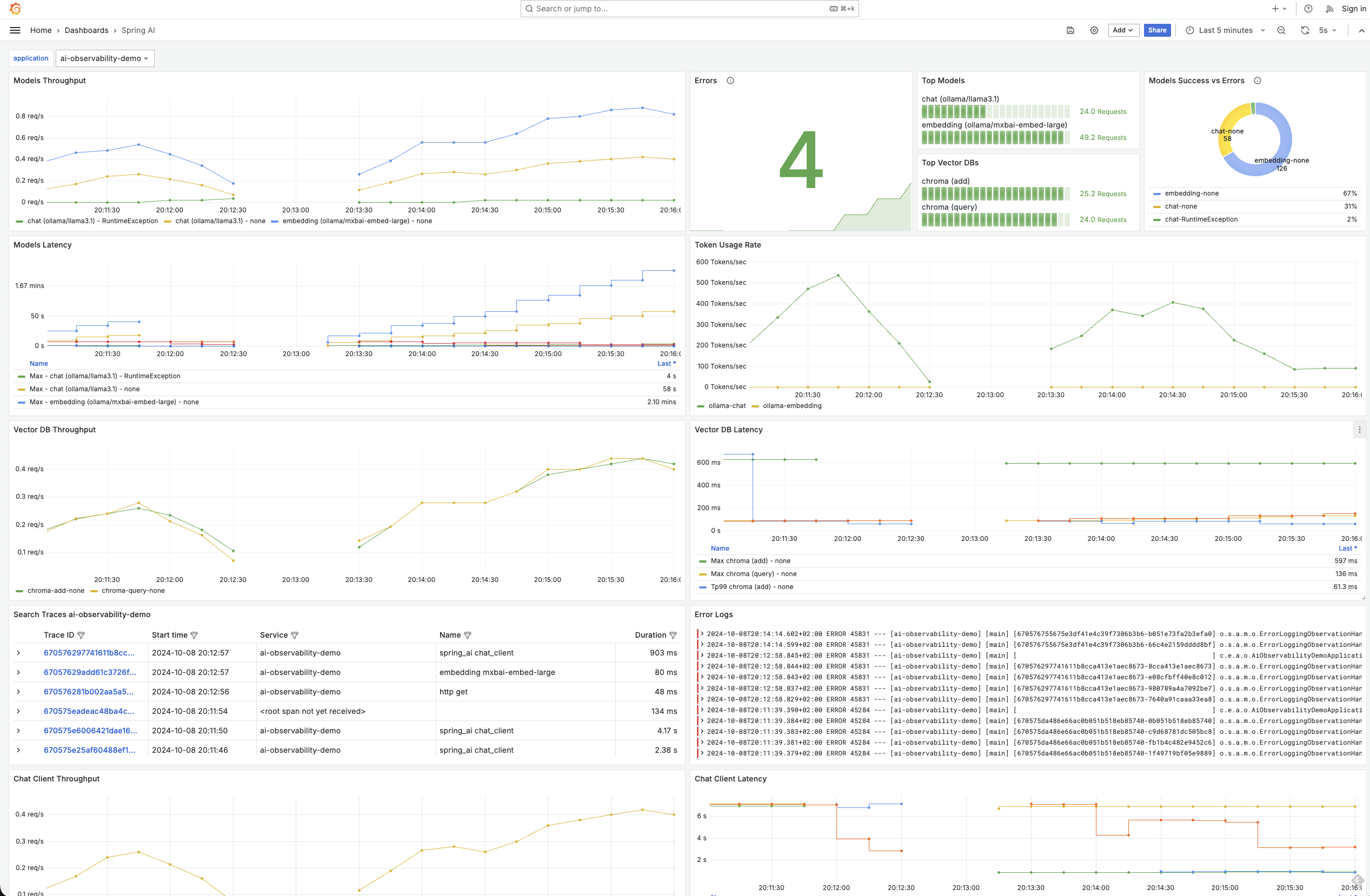
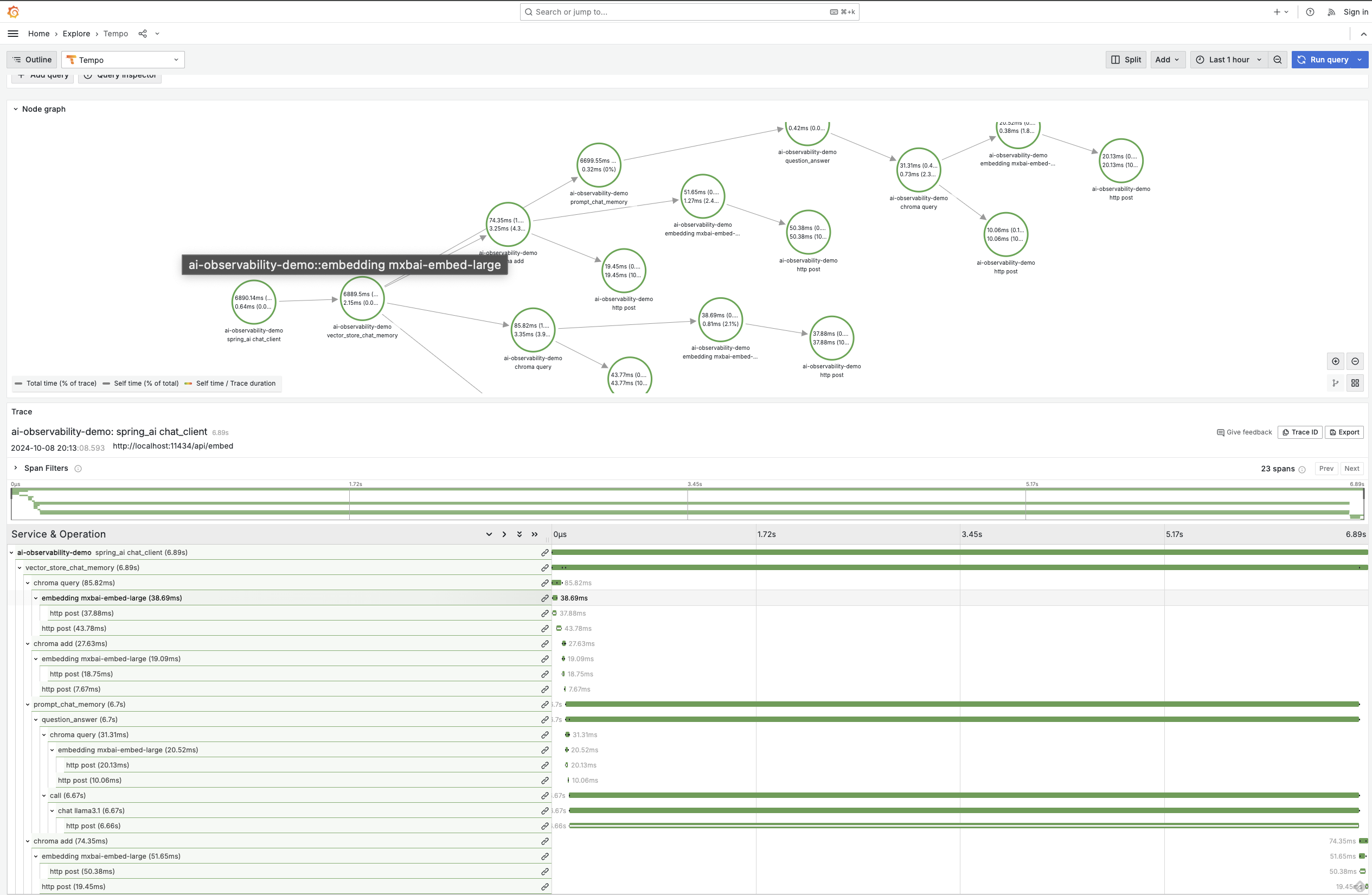
可觀察性涵蓋 ChatClient、ChatModel、Embedding Models 和 Vector stores,使您能夠以精細的細節查看與 AI 基礎設施的所有接觸點。
在 M2 版本中,我們引入了對 OpenAI、OIlama、Mistral 和 Anthropic 模型的可觀察性支援。現在,我們已將其擴展到包括對以下項目的支援:
感謝耿榮為中國模型實施可觀察性。
您可以在可觀察性參考文件中找到有關可用指標和追蹤的更多詳細資訊。以下是一些圖表,用於示範可行的功能。
Spring AI Advisors 是在您的 AI 應用程式中攔截並可能修改聊天完成請求和回應流程的元件。 Advisors 也可以選擇不呼叫鏈中的下一個 advisor 來阻止請求。
此系統中的關鍵角色是 AroundAdvisor,它允許開發人員動態轉換或利用這些互動中的資訊。
使用 Advisors 的主要優點包括:
我們重新審視了 Advisor API 模型,並進行了許多設計變更,並提高了其應用於串流請求和回應的能力。您也可以使用 Spring 的 Ordered 介面顯式定義 advisor 的順序。
根據您使用的 API 區域,可能會發生重大變更,請參閱文件以取得更多詳細資訊。
around advisor 的流程如下所示。

您可以閱讀 Christian Tzolov 最近的部落格文章使用 Spring AI Advisors 為您的 AI 應用程式增強功能以取得更多詳細資訊。
Spring AI 現在支援透過包含鍵值對的 ToolContext 類別,將其他上下文資訊傳遞給 function 回呼。此功能允許您提供可在 function 執行中使用的額外資料。
在此範例中,我們傳入一個 sessionId,以便上下文知道該值。
String content = chatClient.prompt("What's the weather like in San Francisco, Tokyo, and Paris?")
.functions("weatherFunctionWithContext")
.toolContext(Map.of("sessionId", "123"))
.call()
.content();
另請注意,您可以在 prompt 方法中傳遞使用者文字,而不是使用 user 方法。
ToolContext 可透過使用 java.util.BiFunction 來取得。以下是 bean 定義
@Bean
@Description("Get the weather in location")
public BiFunction<WeatherService.Request, ToolContext, WeatherService.Response> weatherFunctionWithContext() {
return (request, toolContext) -> {
String sessionId = (String) toolContext.getContext().get("sessionId");
// use session id as appropriate...
System.out.println(sessionId);
return new WeatherService().apply(request);
};
}
如果您更喜歡自己處理 function calling 對話,您可以設定 proxyToolCalls 選項。
PortableFunctionCallingOptions functionOptions = FunctionCallingOptions.builder()
.withFunction("weatherFunction")
.withProxyToolCalls(true)
.build();
並且透過 ChatModel 或 ChatClient 將這些選項傳遞給模型的呼叫,將會傳回一個 ChatResponse,其中包含在 AI 模型 function calling 對話開始時傳送的第一條訊息。
在事實評估領域中,有一些值得注意的創新,其中一個新的排行榜名為LLM-AggreFact。目前在基準測試中領先的模型是由Bespoke Labs 開發的“bespoke-minicheck”。此模型引人注目的部分原因是,與 GPT4o 等所謂的“旗艦”模型相比,它更小、更便宜。您可以在論文“MiniCheck:高效的事實檢查 LLM 的基礎文件”中閱讀有關此模型背後研究的更多資訊。
Spring AI FactCheckingEvaluator 基於該工作,並且可以與部署在 Ollama 上的 Bespoke-minicheck 模型一起使用。請參閱文件以取得更多資訊。感謝 Eddú Meléndez 在此領域所做的工作。
先前,嵌入文件清單需要逐項呼叫,效能不佳。 Spring AI 現在支援將多個文件批次處理在一起,以便可以在單次呼叫模型中計算多個嵌入。由於嵌入模型有 token 限制,因此會將文件分組,以使每個批次都不超過嵌入模型的 token 限制。
新的類別 TokenCountingBatchingStrategy 會考慮 token 大小並配置 10% 的保留緩衝區,因為 token 估算並非精確科學。您可以自訂自己的 BatchingStrategy 介面實作。
此外,基於 JDBC 的嵌入模型現在可以更輕鬆地自訂在執行大量插入時要使用的批次大小。
感謝 Soby Chacko 在此領域所做的工作以及作為 Spring AI 團隊新成員的其他貢獻。
Azure AI
Vertex AI
許多重構、錯誤修正和文件增強,由廣大的貢獻者共同完成。如果我們還沒處理到您的 PR,請耐心等待。感謝以下人士: