
領先一步
VMware 提供培訓和認證,以加速您的進展。
瞭解更多本文是一系列部落格文章的一部分,探討基於 Java Functions 的全新重新設計的 Spring Cloud Stream 應用程式。
以下是本部落格系列的所有先前部分。
在這篇文章中,我們將研究 Debezium CDC 來源,它允許我們從 MySQL、PostgreSQL、MongoDB、Oracle、DB2 和 SQL Server 等資料庫擷取資料庫變更,並透過各種訊息繫結器(例如 RabbitMQ、Apache Kafka、Azure Event Hubs、Google PubSub 和 Solace PubSub+ 等)即時處理這些變更。
我們還將揭示如何使用 Analytics 接收器 將擷取的資料庫變更轉換為指標,並將它們發布到各種監控系統以進行進一步分析。
本文首先解釋 CDC supplier 和 Analytics consumer 元件,展示如何在您自己的 Spring 應用程式中以程式設計方式自訂和使用它們。 接下來,我們解釋 CDC 來源 和 Analytics 接收器 如何建立在 supplier 和 consumer 之上,以提供開箱即用、隨時可用的串流應用程式。
最後,我們將示範使用 Spring Cloud Data Flow (SCDF) 部署串流管線是多麼容易,這些管線會即時回應資料庫更新,將變更事件轉換為分析指標,並將它們發布到 Prometheus 以便使用 Grafana 進行分析和視覺化。
變更資料擷取 (CDC) 是一種觀察所有寫入資料庫的資料變更,並將它們發布為可以以串流方式處理的事件的技術。 由於您的應用程式資料庫始終在變更,因此 CDC 允許您對這些變更做出反應,並讓您的應用程式以與提交到資料庫相同的順序串流每個資料列層級的變更。
CDC 支援多種使用案例,例如:快取失效、記憶體內資料檢視、更新搜尋索引、透過保持不同資料來源同步來進行資料複寫、即時詐欺偵測、儲存稽核追蹤、資料出處等等。
Spring Cloud Data Flow CDC 來源 應用程式是圍繞 Debezium 建置的,Debezium 是一種流行的、開放原始碼的、基於日誌的 CDC 實作,支援各種資料庫。 CDC 來源支援各種訊息繫結器,包括 Apache Kafka、Rabbit MQ、Azure Event Hubs、Google PubSub、Solace PubSub+。
注意
CDC source 實作嵌入了 Debezium Engine,並且不依賴 Apache Kafka 也不依賴 ZooKeeper! 您可以將 CDC source 與任何受支援的訊息繫結器一起使用! 但是 Debezium Engine 具有一些 限制 需要考慮。
CDC Debezium Supplier 實作為 java.util.function.Supplier bean,當調用時,它將傳遞給定目錄中檔案的內容。 檔案 supplier 具有以下簽章
Supplier<Flux<Message<?>>>
supplier 的使用者可以訂閱傳回的 Flux<Message<?>,它是一系列訊息或 CDC 變更事件,它們具有複雜的結構。 每個事件由三個部分組成(例如 metadata、before 和 after),如下面的 payload 範例所示
{
"before": { ... }, // row data before the change.
"after": { ... }, // row data after the change.
"source": { // the names of the database and table where the change was made.
"connector": "mysql", "server_id": 223344,"snapshot": "false",
"name": "my-app-connector", "file": "mysql-bin.000003", "pos": 355, "row": 0,
"db": "inventory", // source database name.
"table": "customers", // source table name.
},
"op": "u", // operation that made the change.
"ts_ms": 1607440256301, // timestamp - when the change was made.
"transaction": null // transaction information (optional).
}
如果將 cdc.flattening.enabled 屬性設定為 true,則只會將 after 區段作為獨立訊息傳遞。
為了調用 CDC supplier,我們需要指定一個來源資料庫來接收 CDC 事件。 cdc.connector 屬性用於在支援的 mysql、postgres、sql server、db2、oracle、cassandra 和 mongo 來源資料庫類型之間進行選擇。 cdc.config.database.* 屬性有助於配置來源存取。 以下是連接到 MySQL 資料庫的範例配置
# DB type
cdc.connector=mysql
# DB access
cdc.config.database.user=debezium
cdc.config.database.password=dbz
cdc.config.database.hostname=localhost
cdc.config.database.port=3306
# DB source metadata
cdc.name=my-sql-connector
cdc.config.database.server.id=85744
cdc.config.database.server.name=my-app-connector
cdc.name, cdc.config.database.server.id 和 cdc.config.database.server.name 屬性用於識別和分派傳入的事件。 您可以選擇設定 cdc.flattening.enabled=true 來扁平化 CDC 事件,以僅使用其 after 欄位替換原始變更事件,以建立簡單的 Kafka 記錄。 您也可以選擇使用 cdc.schema=true 將 DB schema 包含到 CDC 事件中。
注意
必須將來源資料庫配置為公開其 Write-Ahead Log API,Debezium 才能夠連接和使用 CDC 事件。 Debezium 連接器文件 提供了有關如何為任何受支援的資料庫啟用 CDC 的詳細說明。 為了我們的示範目的,我們將使用預先配置的 MySQL docker 映像。
CDC supplier 是一個可重複使用的 Spring bean,我們可以將其注入到最終使用者自訂應用程式中。 注入後,可以直接調用它並與資料的自訂處理結合。 這是一個例子。
@Autowired
Supplier<Flux<Message<?>>> cdcSupplier;
public void consumeDataAndSendEmail() {
Flux<Message<?> cdcData = cdcSupplier.get();
messageFlux.subscribe(t -> {
if (t == something)
//send the email here.
}
}
}
在上面的偽代碼中,我們注入 CDC supplier bean,然後使用它調用其 get() 方法以取得 Flux。 然後,我們訂閱該 Flux,並且每次我們透過 Flux 接收到任何資料時,都會應用一些篩選,並根據該資料採取行動。 這只是一個簡單的說明,展示了我們如何重複使用 CDC supplier。 當您在實際應用程式中嘗試此操作時,您可能需要在實作中進行更多調整,例如在進行條件檢查之前,將接收到的資料的預設資料類型從 byte[] 轉換為其他類型。
提示
為了建置獨立的、非串流的應用程式,您可以利用 cdc-debezium-boot-starter。 只需新增 cdc-debezium-boot-starter 依賴項,並實作您的自訂 Consumer<SourceRecord> 處理程序來處理傳入的資料庫變更事件。
正如我們在本部落格系列中看到的那樣,所有開箱即用的 Spring Cloud Stream 來源應用程式都已經使用多個開箱即用的通用處理器進行了自動配置。 您可以將這些處理器作為 CDC 來源 的一部分啟用。 這是一個範例,我們運行 CDC 來源並接收資料,然後在將消耗的資料傳送到中介軟體上的目的地之前轉換該資料。
java -jar cdc-debezium-source.jar
--cdc.connector=mysql --cdc.name=my-sql-connector
--cdc.config.database.server.name=my-app-connector
--cdc.config.database.user=debezium --cdc.config.database.password=dbz
--cdc.config.database.hostname=localhost --cdc.config.database.port=3306
--cdc.schema=true
--cdc.flattening.enabled=true
--spring.cloud.function.definition=cdcSupplier|spelFunction
--spel.function.expression=payload.toUpperCase()
藉由為 spring.cloud.function.definition 屬性提供值 cdcSupplier|spelFunction,我們啟用了由 CDC 供應器組成的 SpEL 函數。然後,我們提供一個 SpEL 表達式,用於轉換使用 spel.function.expression 的資料。還有其他一些函數可以透過這種方式組合。請參閱此處以獲取更多詳細資訊。
分析消費者提供了一個函數,用於計算輸入資料訊息的分析結果,並將其作為指標發布到各種監控系統。它利用 micrometer 函式庫,為最受歡迎的 監控系統提供統一的程式設計體驗,並使用 Spring Expression Language (SpEL) 來定義如何從輸入資料計算指標名稱、值和標籤。
我們可以直接在自訂應用程式中使用 consumer bean,以計算傳遞訊息的分析結果。以下是 Analytics consumer bean 的類型簽章
Consumer<Message<?>> analyticsConsumer
一旦注入到自訂應用程式中,使用者可以直接調用 consumer 的 accept() 方法,並提供一個 Message<?> 物件來計算分析結果並將其發布到後端監控系統。
Message 是一個通用的資料容器。每個 Message 實例都包含一個 payload 和 headers,其中包含使用者可擴展的屬性作為鍵值對。 SpEL 表達式用於存取訊息的 headers 和 payload,以計算指標量和標籤。例如,計數器指標可以有一個從輸入訊息 payload 大小計算出的值 amount,並添加一個從 kind header 值中提取的 my_tag 標籤
analytics.amount-expression=payload.lenght()
analytics.tag.expression.my_tag=headers['kind']
分析消費者 (Analytics consumer) 的組態屬性以 analytics.* 前綴開頭。有關可用的分析屬性,請參閱 AnalyticsConsumerProperties。監控組態屬性以 management.metrics.export 前綴開頭。有關組態特定監控系統的資訊,請遵循提供的組態說明。
如同 CDC Source 的情況,Spring Cloud Stream 開箱即用的應用程式也提供了一個基於 Analytics consumer 的 分析接收器。
此接收器適用於 Apache Kafka 和 RabbitMQ 繫結器變體。當用作 Spring Cloud Stream 接收器時,分析消費者會自動組態為從相應的中介軟體系統(例如,來自 Kafka topic 或 RabbitMQ exchange)接收資料。
單獨執行 CDC source 和 Analytics sink 都可以,但 Spring Cloud Data Flow 使它們更容易作為 pipeline 執行。基本上,我們想要編排如下所示的資料流
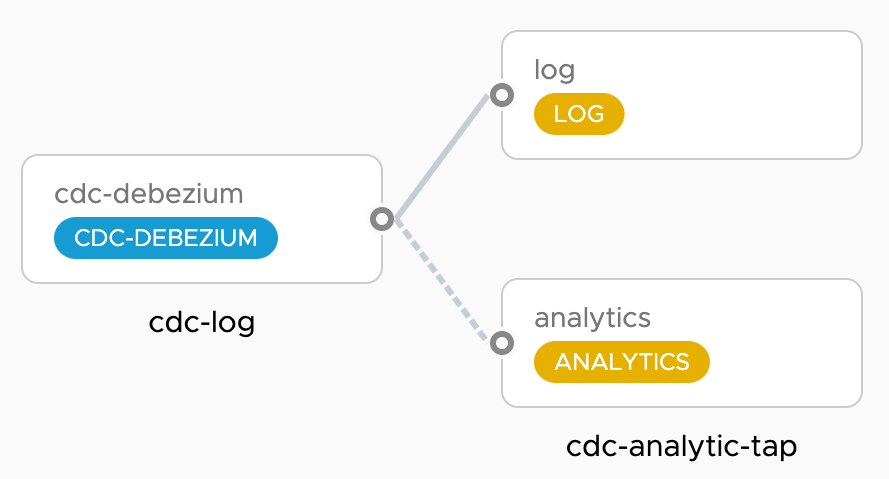
cdc-log pipeline 部署了一個 cdc-source,它使用 JSON 訊息格式將所有資料庫變更串流到 log-sink 中。同時,cdc-analytics-tap pipeline 將 cdc-source 輸出 tap 到 analytics-sink 中,以計算來自 CDC 事件的 DB 統計資料,並將其發布到時間序列資料庫 (TSDB),例如 Prometheus 或 Wavefront。 Grafana 儀表板用於視覺化這些變更。
Spring Cloud Data Flow 安裝說明說明了如何在任何受支援的雲端平台上安裝 Spring Cloud Data Flow。
以下我們將簡要介紹設定 Spring Cloud Data Flow 的步驟。首先,我們需要取得用於執行 Spring Cloud Data Flow 的 docker-compose 檔案,Prometheus 和 Grafana
wget -O docker-compose.yml https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v2.7.0/spring-cloud-dataflow-server/docker-compose.yml
wget -O docker-compose-prometheus.yml https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v2.7.0/spring-cloud-dataflow-server/docker-compose-prometheus.yml
此外,取得這個額外的 docker-compose 檔案以安裝一個來源 MySQL 資料庫,該資料庫已組態為公開 cdc-debezium 連接到的預寫日誌。
wget -O mysql-cdc.yml https://gist.githubusercontent.com/tzolov/48dec8c0db44e8086916129201cc2c8c/raw/26e1bf435d58e25ff836e415dae308edeeef2784/mysql-cdc.yml
mysql-cdc 使用 debezium/example-mysql 映像,並帶有庫存、範例資料庫
我們需要設定一些環境變數才能正確執行 Spring Cloud Data Flow。
export DATAFLOW_VERSION=2.7.1
export SKIPPER_VERSION=2.6.1
export STREAM_APPS_URI=https://dataflow.spring.io/kafka-maven-latest
現在我們已準備好一切,可以開始執行 Spring Cloud Data Flow 和所有其他輔助元件了。
docker-compose -f docker-compose.yml -f docker-compose-prometheus.yml -f mysql-cdc.yml up
提示
若要使用 RabbitMQ 而不是 Apache Kafka,您可以下載一個額外的 docker-compose 檔案,如 RabbitMQ 而不是 Kafka 指示中所述,並將 STREAM_APPS_URI 變數設定為 https://repo.spring.io/libs-snapshot-local/org/springframework/cloud/stream/app/stream-applications-descriptor/2020.0.0-SNAPSHOT/stream-applications-descriptor-2020.0.0-SNAPSHOT.stream-apps-rabbit-maven。
提示
若要使用 Wavefront 而不是 Prometheus 和 Grafana,請遵循 Wavefront 指示。
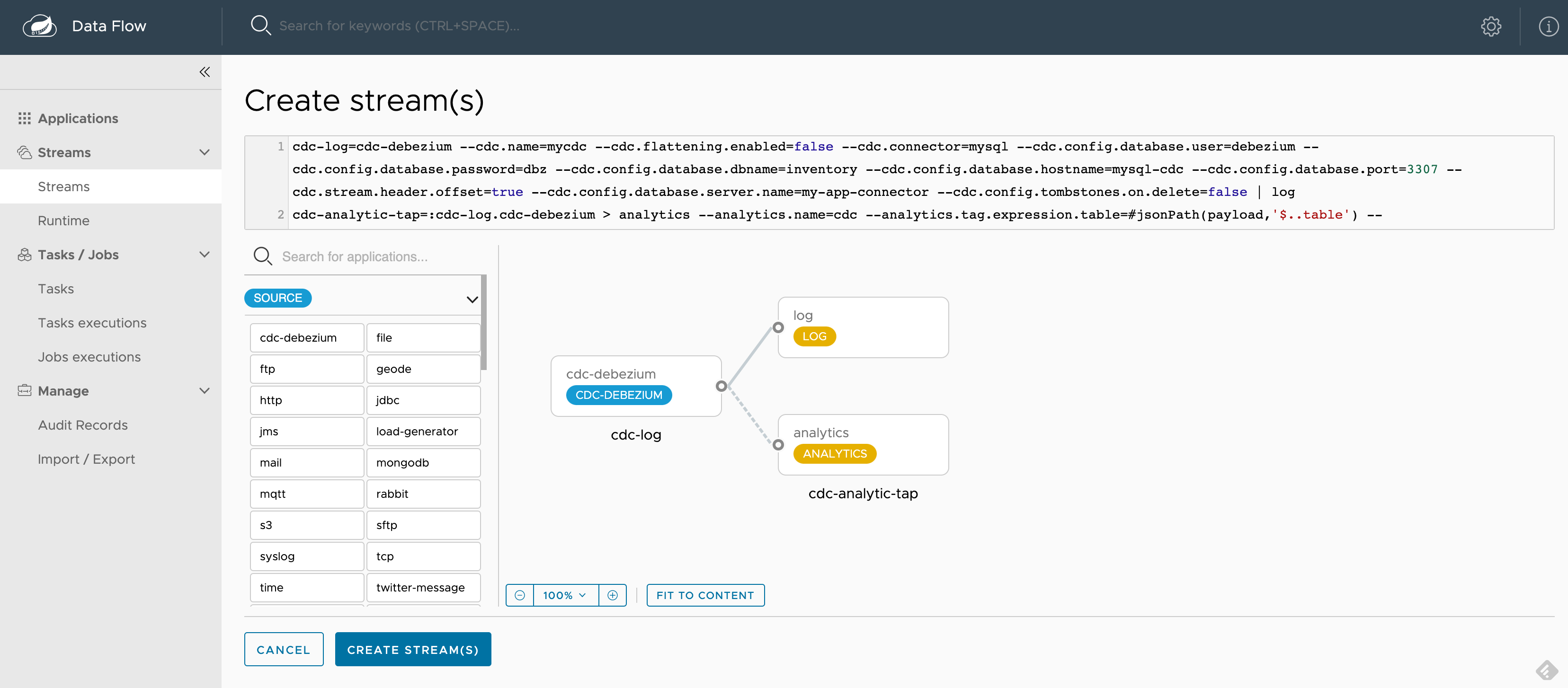
一旦 SCDF 啟動並執行,請前往 http://localhost:9393/dashboard。然後前往左側的 Streams 並選取 Create Stream。從來源應用程式中選取 cdc-debezium,然後從接收器應用程式中選取 log 和 analytics,以定義 cdc-log = cdc-debezium | log 和 cdc-analytic-tap = :cdc-log.cdc-debezium > analytics pipeline。您可以點擊應用程式的選項以選取所需的屬性。
為了更快地引導啟動,您可以複製/貼上以下現成的 pipeline 定義程式碼片段
cdc-log = cdc-debezium --cdc.name=mycdc --cdc.flattening.enabled=false --cdc.connector=mysql --cdc.config.database.user=debezium --cdc.config.database.password=dbz --cdc.config.database.dbname=inventory --cdc.config.database.hostname=mysql-cdc --cdc.config.database.port=3307 --cdc.stream.header.offset=true --cdc.config.database.server.name=my-app-connector --cdc.config.tombstones.on.delete=false | log
cdc-analytic-tap = :cdc-log.cdc-debezium > analytics --analytics.name=cdc --analytics.tag.expression.table=#jsonPath(payload,'$..table') --analytics.tag.expression.operation=#jsonPath(payload,'$..op') --analytics.tag.expression.db=#jsonPath(payload,'$..db')
cdc-log pipeline 部署了一個 cdc-debezium source,它連接到 mysql-cdc:3307 上的 MySQL 資料庫,並將 DB 變更事件串流到 log sink。有關可用的組態選項,請參閱 cdc-debezium 文件。
cdc-analytic-tap pipeline 將 cdc-debezium source 的輸出 tap 到 analytics sink 中,並將 cdc 事件串流到 analytics sink。分析建立一個 指標計數器 (稱為 cdc),並使用 SpEL 表達式 從串流訊息 payload 中計算指標標籤 (例如 db、table 和 operations)。
例如,讓我們修改 MySQL inventory 資料庫中的 customers 表。更新交易作為變更事件傳送到 cdc-debezium source,後者將原生 DB 事件轉換為如下所示的統一訊息 payload
{
"before": {
"id": 1004, "first_name": "Anne", "last_name": "Kretchmar", "email": "[email protected]"
},
"after": {
"id": 1004, "first_name": "Anne2", "last_name": "Kretchmar", "email": "[email protected]"
},
"source": {
"version": "1.3.1.Final", "connector": "mysql", "server_id": 223344, "thread": 5,
"name": "my-app-connector", "file": "mysql-bin.000003", "pos": 355, "row": 0,
"db": "inventory",
"table": "customers",
},
"op": "u",
"ts_ms": 1607440256301,
"transaction": null
}
以下 SpEL 表達式用於從 CDC 訊息 payload 中計算 3 個標籤 (db、table、operation)。這些標籤會分配給發布到 Prometheus 的每個 cdc 指標。
--analytics.tag.expression.db=#jsonPath(payload,'$..db')
--analytics.tag.expression.table=#jsonPath(payload,'$..table')
--analytics.tag.expression.operation=#jsonPath(payload,'$..op')
以下螢幕擷取畫面顯示了選取所有屬性後的外觀
建立 和 部署 cdc-log 和 cdc-analytics-tap pipeline,接受所有預設選項。您可以選擇使用 Group Actions 同時部署兩個串流。
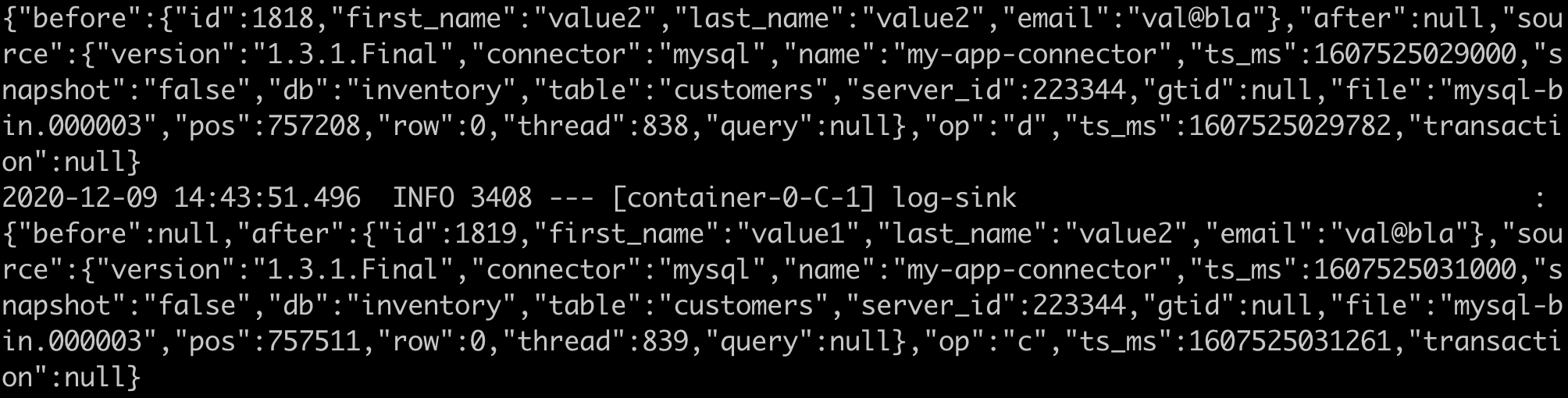
部署串流後,您可以透過 SCDF UI 或使用 Skipper docker 容器檢查已部署應用程式的日誌,如文件中說明。如果您檢查 Log sink 應用程式的日誌,您應該會看到類似於以下的 CDC JSON 訊息
接下來,使用 按鈕 (或直接開啟 localhost:3000) 前往 Grafana 儀表板,並以使用者:`admin` 和密碼:`admin` 登入。您可以瀏覽 Applications 儀表板以檢查已部署 pipeline 的效能。現在您可以匯入 CDC Grafana Dashboard-Prometheus.json 儀表板,並看到類似於以下的儀表板
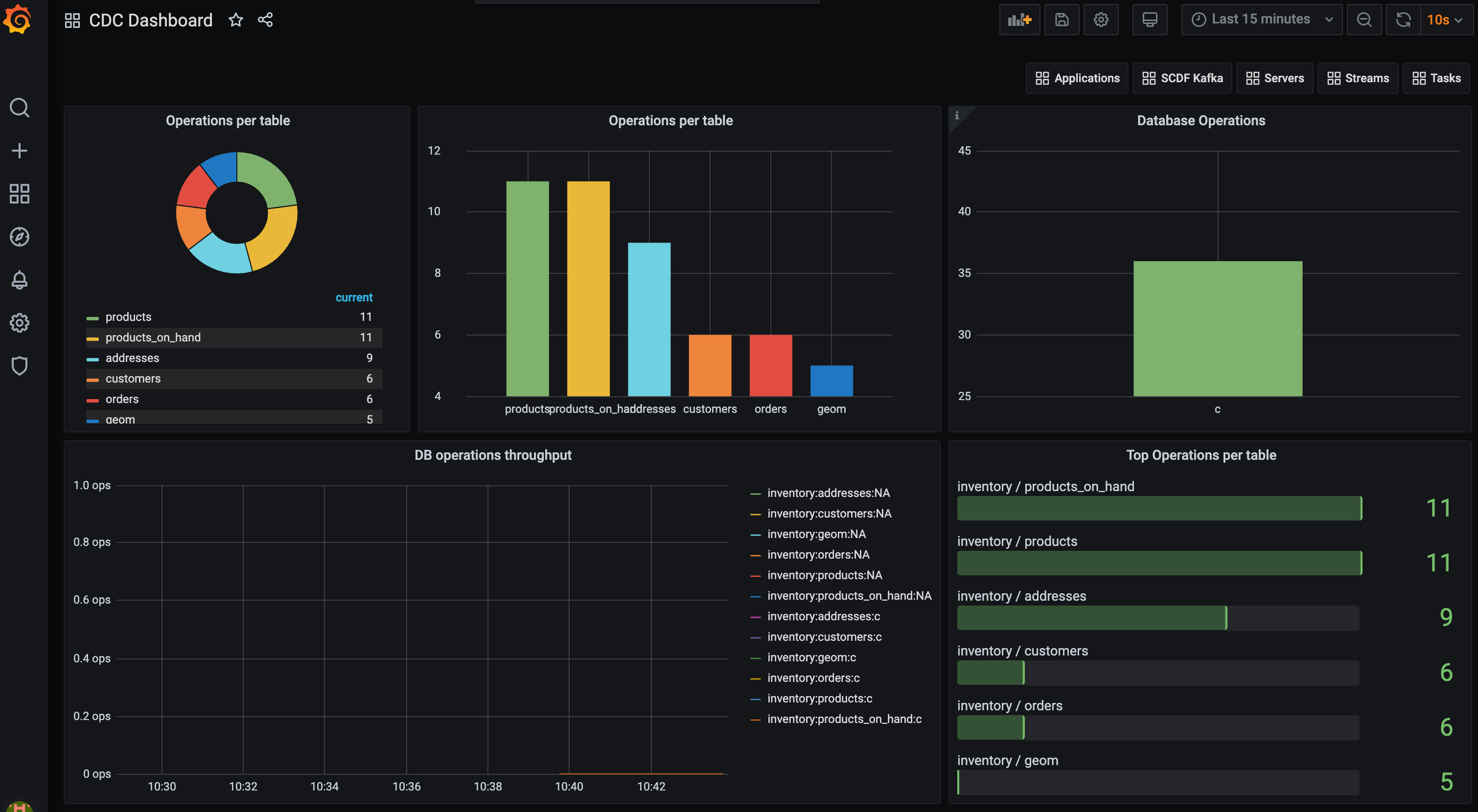
以下查詢已用於匯總 Prometheus 內的 cdc_total 指標
sort_desc(topk(10, sum(cdc_total) by (db, table)))
sort_desc(topk(100, sum(cdc_total) by (op)))
提示
您可以開啟 Prometheus UI,網址為 http://localhost:9090 以檢查組態以及執行一些臨時 PQL 查詢。
您可以連接到 localhost:3307 上的庫存 CDC MySQL 資料庫 (使用者:root 和密碼:debezium),並開始修改資料。
以下 docker 命令顯示如何連接到 mysql-cdc
docker exec -it mysql-cdc mysql -uroot -pdebezium --database=inventory
以下指令碼有助於產生多個插入、更新和刪除 DB 交易
for i in {1..100}; do docker exec -it mysql-cdc mysql -uroot -pdebezium --database=inventory -e'INSERT INTO customers (first_name, last_name, email) VALUES ("value1", "value2", "val@bla"); UPDATE customers SET first_name="value2" WHERE first_name="value1"; DELETE FROM customers where first_name="value2";'; done
您將看到 log-sink 日誌反映了這些變更以及 CDC 儀表板圖表的更新。
在這篇部落格中,我們看到了 CDC-debezium 供應者和 Analytics 消費者函式,以及它們對應的 Spring Cloud Stream 來源和接收器如何運作。 供應者和消費者函式可以注入到自定義應用程式中,以便與其他業務邏輯結合。
來源和接收器應用程式開箱即用,可用於 Kafka 和 RabbitMQ 中介軟體變體。
您可以輕鬆構建獨立應用程式,將 Cdc-debezium 供應者與 Geode 消費者結合使用,以建立和維護資料庫資料的記憶體內視圖。 同樣地,您可以將 Cdc-debezium 供應者與 Elasticsearch 消費者結合使用,以即時維護資料庫資料的可搜尋索引。
更令人興奮的是,您可以使用 OOTB cdc-debezium 來源、geode 接收器和 elasticsearch 接收器應用程式來實現上述場景。 您可以在不同的訊息繫結器和來源資料庫上構建這些管線。
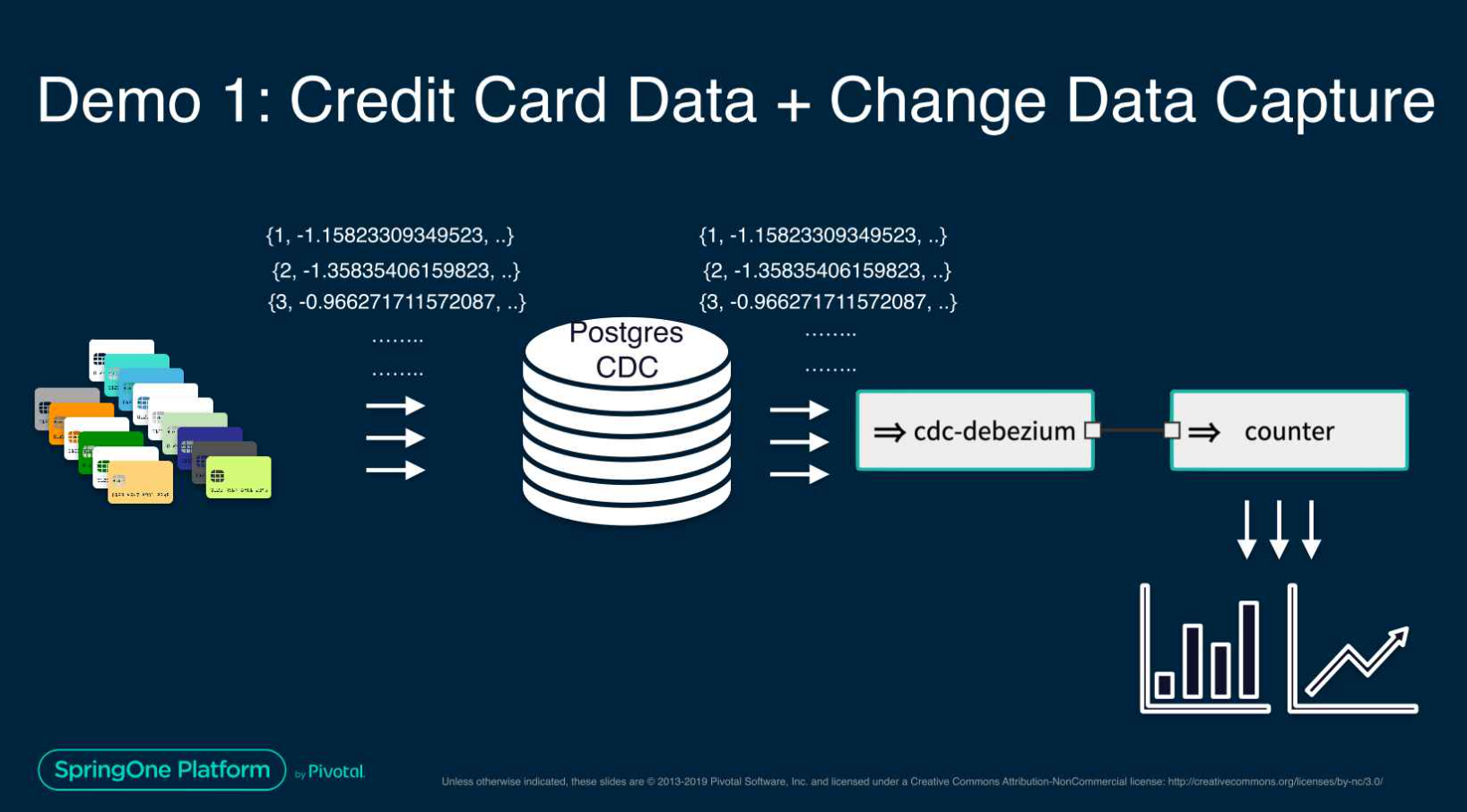
這個 Spring One 演示展示了一個進階的使用案例,使用 CDC-debezium 和機器學習來構建信用卡詐欺檢測的串流資料管線。
在這個部落格系列中,我們還有幾個即將推出的章節。 請繼續關注。